











How to Build a Super Collective Intelligence
When 1 + 1 = 42
How to Build a Super Collective Intelligence
When 1 + 1 = 42
DISCLAMER: This is the Sh*tTY first draft
This is the embarrassing, shitty, unedited, unreviewed, draft of the first few chapters intentionally released as is. Why am I releasing it as is? I don’t know, to learn perhaps… I’m continuing to actually build and test out what I’m writing about here. This may make writing a moot point, but I find it helpful to write things down and structure my thoughts.
Humans, barely intelligent
Humans, barely intelligent

Source: www.gifbay.com/gif/stupid-12

Source: https://giphy.com/search/stupid-people

Source: https://giphy.com/search/stupid-people
We may think that the greatest challenge to humanity today is something like Superbugs, Climate change, inequality, nuclear proliferation, synthetic biology, artificial intelligence, millennials, or a large number of other things that keep us awake at night. But what is the common theme behind these, is there an underlying cause? When we think of global challenges, most of them do have a common cause, humans. Climate change is caused by unsustainable human activity, inequality is fostered by greed and imbalance of power, and millennials, of which I am one, well it's obvious, they are the result of a failed lab experiment crossing a cheeseburger with a Nokia 6210. Now sarcasm aside, If we were to somehow solve these challenges, I.E the symptomes, but not the underlying cause, will New challenges not just pop up in their place? Can we imagine a solution to the underlying cause?
What is the underlying cause here? One possible cause could be that we simply don't have the cognitive capacity and intelligence to think holistically, taking into account the hugely complex systems we live in. A solution to one problem is often the cause of multiple others. If we consider human intelligence, compared to other intelligences, then we have just about the very minimum intelligence anything could have to recognize it is intelligent, but we may be nowhere near the intelligence we need to actually think intelligently. Consider a baby who has just learned to walk, suddenly they are filled with confidence and overestimate their skills. They think they can walk anywhere, cross a busy street, walk into a swimming pool, or straight down a flight of stairs. A baby's confidence in their skill of walking is nowhere near the reality of their skill level. This is a well known cognitive bias and applies to humans of all ages, known as the Dunning-Kruger effect which states that after you know the basics, the less you know, the less you are able to understand how incompetent you actually are, and therefore, ironically, the more confident you are that you know more than you actually do.
To illustrate this point, I made this chart below
Is there a way we can increase our intelligence, our maturity, our empathy, our wizdom? And I'm not talking about linear growth and a marginal increase of 5% 10% or even 20% higher. For these types of increases our educational systems are good enough, but still bring us nowhere close to where we need to be. I’m talking about a 5x 10x or 200x improvement that is required for us to cross the intelligence requirement gap.
When 1 + 1 = 42
An ant colony is orders of magnitude more intelligent than a singular ant, a brain is orders of magnitude more powerful than a single neuron, bacteria which on its own can survive only for a few minutes in harsh environments, however, can thrive and grow exponentially in the same harsh environment when networked together with millions of other bacteria that openly share genetic information. It is the argument of this paper that it is our highly networked and somewhat open structure that has enabled us to get this far, and that we can rapidly accelerate progress, become more intelligent, more compassionate, more mature, more conscientious, and solve our grand global challenges that currently seem so complex, by embracing this. In this paper I’d like to describe why this is important, what this means and how it could be achieved, in the hope that together we can build an awesome tomorrow.
Oh, and I’m also recording this as an audio/video podcast, because personally I battle to read, my dyslexia turns even the shortest post into a marathon read. Therefore in the hope to encourage others to also create audio version of what they write, i'm doing it here too.
Accounting for my own bias
Before reading further, it will be useful to understand a little about my background as it will help you to know what biases may be distorting my own perceptions of reality and therefore the assumptions and conclusions I write up here.
The work I’ll be describing here started from the flames and rubble of many failed projects and businesses I tried to start in my early career. It gradually coalesced into a coherent project with the birth of my first child and a desire to help my kids become self-directed learners, willing and able to tackle crazy, awesome challenges.
Soon after my daughter was born I started Dev4X, a company I started as a side project, that would focus on developing audacious projects that on the face of it would have little chance of success, but if they did would change the world for the better. The assumption was that there were many people in the world who wanted to do something more meaningful than the bullshit jobs they were spending most of their time on. If we could somehow tap into their wasted talents, for just a few hours a week, to do something meaningful, some modular small task that when stacked together with many thousands of other modular small tasks, that together we could create something amazing. If done openly, then even if a project failed -which was the expectation from the start- then most of the work we put into it would not be wasted, the modularity of the tasks that were completed could then be applied to a different projects (A detailed description of how this is done is described later in the paper). I started with various projects that focused on empowering kids, with the first large project trying to help kids in refugee camps, disaster areas and rural areas who don't have access to school, to help them take their learning into their own hands. We called this the Moonshot Education Project, and here we focused on building a GPS-like learning map, that could help these kids see where they are at on a map of everything they can learn and empower them to self-navigate to where they want to go, learning what they need, when they need it. Now suddenly their passion to become a Nurse or bicycle mechanic translated into a personal path of learning that was relevant to their goals. This approach allowed us to leverage their innate personal motivations as opposed to relying on external motivators like teachers, and parents, which were not around. A few years later, while working with various universities, NGO’s and UNESCO I started to explore the same challenge but from a different angle, empowering kids to tackle real-world problems and to tie those goals to the things they should learn, we called this the Open Social Innovation project. Here kids would be empowered to build solutions to their local challenges, like building a water purifier, a solar electric power supply or an electric wheelchair. Here each project would be broken down into many small modules, and all modules shared openly, so that others trying to solve similar challenges would not need to start form step one, but could leverage the work others have already done.
Then, suddenly life happened, and all I was doing became really personal. My 5-year-old daughter suddenly became paralyzed over the span of a few hours, due to a rare illness. During those first few days in the hospital, after finding out there were no treatments we could afford, and only a 2% chance of recovery, we decided to use this as an opportunity and put to practice the work I had been doing over the past few years. We decided to build a solution to help her regain the use of her paralyzed limbs.
First, using the learning map method from the moonshot education project, we mapped out where we were and where we wanted to get to, which showed us all the things we needed to learn. Like 3d printing, electronics, signal processing and machine learning. Then we used the Open Social Innovation method, to start building and learning as we went, reaching out to strangers from around the world to share their expertise and advice.
Every day we worked to solve her challenge, and soon we were working with hundreds of experts from around the world. We mapped out all we needed to learn, and applied Open Social Innovation to build all we needed to build. A year later, leveraging the collective intelligence of strangers from around the world, she and I built a brain-controlled exoskeleton, 100X cheaper, 10X lighter, and one that enabled her motor neurons to repair themselves. Her story is really inspiring, but more so, it was a powerful validation of what I've been working on. Which is to radically increase innovation, by accelerating learning and doing within a highly modular, open network.
This brief snapshot of relevant parts of my background will help inform you where I am coming from for the rest of the post, including what my biases are, and the perspective that shape my vision.
Creating The Context.
Humanity has for many thousands of years already started building a collective intelligence, but before we jump into it, in this section, I’d like to accomplish two main goals: 1. Provide context for the remainder of the paper and 2. Use this context generating process as a tangible example of how super collective intelligence can be generated.
Let’s start with context: This is really important, because a lot of what I want to discuss here needs to be viewed from a Macro, global perspective, and not through our individual local contexts we live in. Local contexts vary considerably, and local solutions in one context may actually harm efforts in other contexts. As an example, as I write this, New York City where I live is going into lock down due to the coronavirus. It's an important local solution, but unfortunately something that is harming efforts to contain the virus in other localities as some New Yorkers, move to other locations not in lock down. The same is happening in South Africa where I grew up and in India, where I now spend a lot of time working. There, due to the lock down, migrant workers who are no longer able to find work in the city, are returning to their villages, and there, the result may be catastrophic. One local solution is creating challenges elsewhere. For this reason, I want us to take a step back, way back, let's choose to put to one side our local contexts, like our political structures, our economic structures, our existing local solutions. Let's boil the challenge down to a point where it cannot be distilled any further, and I want to try and do this by discussing the context.
Humans have developed a complex world built on centuries of ideas, stacked on top of each other like bricks, many of which we now simply take for granted. And while many of these idea bricks are powerful and have been vetted rigorously, on occasion some crack or are no longer fit for purpose, but could be hidden from sight as so many other bricks are stacked on top of them. While I will mention how some of these bricks are cracked or how they are unfit, I want to start far below them, I want to start with a new foundation, on top of which those cracked broken bricks may not even be required.
Context modularity
When discussing ideas that require us to come back to first principles and build them from the ground up, we need to painstakingly build a new shared understanding. Consider the trouble Tim Berners-Lee, the inventor of the World Wide Web had when he first started to pitch the World Wide Web. At that point there was no mainstream shared understanding, no context that could be leveraged to help him create an easily understood 30 second elevator pitch for the public. His 30 second pitch was: “I want to take the hypertext idea and connect it to the TCP and DNS ideas” … Mmmm ok, this is still confusing today, but back then in the late 80’s and early 90’s this could have as well been a different language. Tim and a vast group of collaborating engineers had to create a new shared understanding, a new way of describing things and communicating things, a new context. You can imagine them building this context over time one idea at a time, with each new idea able to be stacked together with other ideas gradually building a sophisticated shared understanding. So let's do that here, but let's do it a little differently.
Unlike traditional shared understanding, like how the earth was thought to be the center of the universe, and when we discovered it was not, became incredibly difficult to amend, replace or remove from our world-views, let’s make sure the ideas we build here ARE interchangeable, amenable and easily replaced! I’m well aware that I may be wrong on occasion, in fact, I hope I am, so that I can demonstrate how easily it is to quickly replace some brick of shared understanding with a more accurate brick. As we will discuss later on in this post, one of the key elements of a powerful collective intelligence is the ability of it to rapidly refine, reuse, and replace information. I think a reasonably good analogy is to think of ideas as Lego bricks. Bricks which should be designed to easily be stacked together, swapped out for others, recombined with yet others, localized, amended or scrapped altogether without needing to totally dismantle all you have built.

lego brick by Lluisa Iborra from the Noun Project
Lego bricks work because they have a simple modular structure, they have an input side, where the indents are designed to be able to accommodate certain other bricks, they have a shape, design and color which gives the brick its meaning and purpose. And they have the output side, where other bricks could be stacked on top.
And that’s what I want to do here first, I want to start by building the context bricks with which I’d like to discuss Super Collective Intelligence.
How the rest of the book will be structured:
The way I am writing this book and how it is structured is meant to also be a tangible example of how super collective intelligence can be generated. One idea building on-top of another until the sum is far greater than it’s parts.
We will start off describing the Context bricks,
Then the foundational bricks that can be built on top of that context,
Then the solution bricks that can be built on top of that foundation,
Then the Implementation bricks
And finally ending with the scale bricks
lego brick by Lluisa Iborra from the Noun Project
Context Bricks 1 - We are in deep shit
But Shit makes for really good compost, out of which we could grow something amazing!
Context Bricks 1 - We are in deep shit
But Shit makes for really good compost, out of which we could grow something amazing!
We are in deep shit, but this is a huge opportunity
The goal of this chapter is to define some initial bricks around the extent of the challenges ahead, and how deeply rooted, and therefore foundational they are. Deep rooted, foundational challenges require a special solution, usually one that requires a complete rethink. And this is the key point of this chapter, the idea that our current challenges cannot be solved by business as usual, in fact, I hope to show that we cannot even rely on our foundations. We need to take this all the way down to first principles.

Consider the leaning tower of Pisa. Over the two hundred years of its construction it started to lean quite early on, the foundations on the one side of the building were poorly developed and lay on softer ground. And even though they could have rebuilt the foundations when they were still early on in its development, this was considered too costly, so they instead tried to mitigate the leaning by building further layers slightly curved in the opposite direction of the lean to counter the lean of the building. In the end even this did not work and over the years modern engineers have tried to reinforce the foundations by injecting them with cement grouting and attaching cables boulted around the tower to try to hold it in place. The modern world is built much like the leaning tower of pisa, on faulty foundations. And much like the architects and builders of the tower, we have been trying to mitigate this challenge by building solutions that focus on the symptops (the lean) instead of the cause (the faulty foundations).
The world is going through tremendous challenges over the short to medium term, particularly over the next 25 years. Climate change, Job disruption, nuclear proliferation, synthetic biology, superbugs and income inequality, to name just a few. The challenges we will face, while individually, are similar to those humanity has faced many times before like automation causing job loss, now however, because we are facing them all at once and at an increasing rate, they could quickly outpace the speed at which our traditional mechanisms have been able to generate solutions. It could quickly cause our leaning tower to collapse. This seems already to have been the case for some parts of our tower. Let me expand on this using two points:
Point 1, You realize we still need to pay back our credit cards:
If you have watched TED talks, then perhaps you already know of Dr. Hans Rosling who beyond being a TED rockstar was also a profoundly compassionate humanitarian. In some of his talks, and his recent book, Factfulness, he described the world through data and showed how incredibly far we have gotten as humans and how good we have it now compared with the past. If we look at the data, it's incontrovertible that we are far better now in many important ways than ever before. People who are living in absolute poverty is diminishing rapidly, child mortality has dropped many fold since measurements began, girls are getting an education and we now have more flavors of salad dressing than there are active conflict zones on our planet. Many others share similar points, Like Dr. Peter Diamandis, author and founder of the XPRIZE, among numerous other accomplishments. He too makes a great case in his book “The future is better than you think”. A few years back when I worked with him on one of his ventures, Planetary Resources, an asteroid mining company, we spoke of how soon modern technologies could foreseeably deliver to us an abundance of anything we can think of, including gold, platinum and other rare earth metals, from asteroids. These are strong arguments, backed up with data. Today is far better than the past, and likely advances that are soon to come about will expand on this progress greatly. However, what is missing is what has fueled this progress. And how in the short to medium term we can expect to fuel continued progress, or even to simply sustain the burn rate we currently have. We need to realize we still need to pay back our credit cards. If we look at data coming out of the UN, described in more detail in point 2 below, this progress, however amazing it is, has come at a huge price, a price we have not yet paid. The progress has been funded unsustainably, by the natural resources of our planet. It's similar to how you can temporarily increase your standard of living by putting things on a credit card. For example, almost anyone reading this piece could easily increase their standard of living temporarily, by getting a few new credit cards. You could then pay for the surgery you need, the education your kids lack, and the care your parents deserve, You could buy that new car, an 8K TV, go on holiday, eat out and go to extravagant parties (well maybe not for the next few months). And in all accounts the quality of your life, and those around you would increase. But give it a few months or sometimes a few years -for those talented enough at conning their way to more credit- and things will eventually catch up to you. Yes I agree with Dr. Rosling and Diamandis, that things have gotten a lot better, and that the future could become far better than we think, but this progress has created huge dept, just like credit card debt, which will need to get paid back, with interest. One option, which I’ve heard increasingly spoken about, especially by climate change deniers, or those well off few, is to simply continue the rapid resource extraction by unregulated mega corporations and oligopolies. Allow the free market and the invisible hand to guide humanity to a more valuable short term future - valuable for the small number of shareholders that is. Then as we bankrupt earth, hope to travel the stars in search for a few replacement planets that we could move to. Let’s consider this quickly: There are many natural examples of this happening: A reptile as they first grow up in their egg uses up all the resources of that egg before they bankrupt it’s resources, break free from it and move into to a completely new environment. We could consider earth as being the egg of human civilization. But an obvious counter to that is, what about all the non-human life that also calls the earth their home, many of which we have already brought to extinction. I consider this option here, not because I believe we should take it, but because it is a valid option and one we may need to take assuming we do little to change and we don't destroy each other before this is possible. There is also the option to hope we invent some technologies that could help us start to become more sustainable, and there are numerous such technologies currently in the pipeline. From renewable energies, water desalination, vertical farming to synthetic biology. But the rate of these advancements are simply too slow. At our current pace, even taking into account these technologies, we are on track to lose as much as 30 to 50 percent of all species on the planet by 2050.
Point 2, We need to Marie Kondo the shit out of the world
If the goal is to retain the Earth, then the costs of paying back this Progress Debt, could far exceed the monetary value we have extracted from it, similar to how paying back a car on credit will cost you more in the long run than it would have had you paid for it with cash. I do get the opportunity cost argument, that sometimes it’s far more advantageous to put things on credit if the interest rates are low and the return on investment of that purchase exceeds the interest payments, but here things get scary. It’s not those that created this Progress Debt that will need to pay for it! Those that created this dept will be far gone when it's time to pay it back, and for them it was a bargain, for them the opportunity cost calculation made sense, for them the cost has been zero. They never needed to pay anything back, they effectively got to take out this progress dept at 0% interest without the requirement to even pay back the principal. But that calculation is not as favorable for our kids and future generations, they are the ones that will need to pay back this dept, assuming they want to keep the earth habitable. Let me illustrate just how much debt we now have by looking at what we have spent this debt on, and how little of that is actually providing us a net positive return on investment: A report funded by the UN conducted a multi year deep analysis of the top 100 industries, with a seemingly simple objective. Add all the REAL costs of the industry to their balance sheets and see which would still be profitable. The report showed that greater than 90% of the world’s top industries would not be profitable if they paid for the natural capital they used and damage they are doing. If you were to add their externalized costs, which are costs that companies don't pay I.E the Progress Dept, and you add that to their balance sheets, they would not be profitable. For example the forestry industry don't pay for the true cost of the forests they cut down, oil companies don't pay for the pollution and damage they create, the garment industry does not pay to remove microfibers from our water supply. Almost all of the top 100 industries are in the same place. Think about what that means. It means that almost everything we spent our credit on was spent on assets that cost us more than they provide as a return. Instead of purchasing things we needed and would have caused a net positive investment for us, we blew it on bullshit short-term extravagances. Imagine the whole world were represented by the following family:
Instead of purchasing the laser eye surgery they needed, they purchased a nose job instead
Instead of getting their kids a better education, they spent it on sending them to glorified daycares
Instead of getting their parents the care they needed, they bought them pain killers.
Instead of buying the car they needed, they bought a 6.2 liter SUV’s to do their grocery runs with.
Almost everything this family has spent their credit card money on, while temporarily increasing their standard of living, were really poor investments. None provide them any real net return, and simply compound the debt they will need to pay back.
What this means is that if we want a sustainable world, one in which our kids can still live, we need to fundamentally change how the world does almost everything it does, from the way we create toothpaste and build our homes, to the way we produce our coffee and the socks we wear. All those industries, all those factories, all those shops, and means of production will need to fundamentally change. Consider how disruptive it would be for you to change almost everything you currently do. This is the extent of change we need to aim for if we want a sustainable future. I know this sounds impossible, but bare with me for a second. Let’s forget what is possible for a second and come all the way down to first principles. Let's imagine we could redesign everything.
Re-engineering almost everything we are doing is a huge challenge but also a huge opportunity. Consider how much better we could design the world now with the experience we have gained over the past few thousand years. Disruptive innovation could not only come to replace unsustainable industries, it could provide educational and occupational opportunities that don't currently exist, outpacing the jobs being lost, and in their place create sustainable jobs, which inherently would be far more fulfilling and meaningful, than the bullshit jobs available today. Later in this post I go into detail discussing how we can go about rapidly re-engineering the world from the ground up, using a technique we see numerous natural collective intelligent systems use, like bacteria.
Therefore to conclude this chapter, here we described the first few context bricks we will use during our discussions. Each of these bricks will be reused and recombined with others later in the paper and to visually make this more interesting and understandable, I’ve created these bricks here:
Note that as we go, you may have disagreements with the ideas I’ve discussed. It would be useful to focus your disagreement onto one or many of these bricks, highlighting where you think the input, idea or output need to change. Jointly we could then decide if we should update, replace or possibly fork -which is essentially, creating a copy of something making some changes to it and then running both versions in parallel (A concept I’ll dive deeper into later in the paper).

[needs updating] Context Bricks 2 - Our ignorance is increasing
That's ok, but we need a framework within which to collaborate in a world of increasing divergence.
[needs updating] Context Bricks 2 - Our ignorance is increasing
That's ok, but we need a framework within which to collaborate in a world of increasing divergence.
[NEEDS Updating, Add technical examples, cost calculations…]
Our ignorance is increasing rapidly
In this chapter I want to continue describing some contextual bricks that form the terrain on top of which we need to build, but from a different angle. This is a big one for the medium to long term and may not seem to be relevant for the next few years, however this is an illusion, these challenges will be creeping up really quickly given that they are exponential in nature. Meaning that while today it may be manageable, next year it could be double in size, and the following year, doubling in size again, and then again and again… Discussing this challenge here will help frame the conversation around collective intelligence, education, open innovation and our limited personal capacity to learn everything there is to learn. Here I describe how the amount of knowledge we need to function is increasing exponentially, and inevitably will exceed the capacity of our brains to learn, retain and pass on that knowledge. I’ll share some ways we have overcome this challenge in the past and how we can learn from that to radically increase our capacity to learn in the future.

Source: https://imgur.com/gallery/zgXHFNg
Collective intelligence is an emergent property of certain types of networks, like an ant colony. Here the collective intelligence of the Ant colony does not require the singular ant to understand everything, it just requires the ant to operate within a framework where collective intelligence can emerge. Do we need humans to understand everything? Is that even possible? Can we create such a network and an appropriate framework for us humans, where, while individually we may not understand everything, collectively we do? Do we already have such examples and could we expand on those and increase their capacity?
Let's start by looking at how human networks first started. This has been a personal fascination on mine for many years, and two research books stand out of the many I've read namely, Sapiens by Prof. Yuval Noah Harari, and Blueprint by Nicholas A. Christakis MD PhD. Each of these books, considers our history in extraordinary detail, some of which I want to highlight here: Let’s first consider prehistoric humans, hunter gatherers, traveling in small family groups, roaming the land in search for food and shelter. Back then, within a decent lifetime you could learn all there was to learn about foraging, hunting, food preparation and survival skills. From your perspective you could learn and know all there was to learn and know within a lifetime. This is not unlike the experience of other animals, who within their lifetimes also learn all there is to learn from their perspectives. A lion learns how to hunt and survive by first playing it out while they are young cubs, then later they learn through experience and the environment, by the time their lives end, there is little new they could have learned from their perspective. Sure, they probably did not contemplate the theory of relativity, but they also did not need to in order to catch the gezel drinking at the river's edge. And for about 2.5 million years prehistoric humans lived like this, similar to our animal brothers and sisters, we learned and knew all we needed to and this was the capacity to which our brains evolved to handle. Then 70 thousand years ago, looking at the archaeological record things started to change. Our brains were suddenly in a position where they needed to accomplish much more than they were evolved to handle, and yet we managed this. But How? This could not simply have been evolution. Evolution takes millions of years, and yet somehow we managed to extend our mental capacities within thousands of years.
Before we discuss some of the ways we managed to do this, let’s first put to rest some pseudoscience about the human brain. There is a myth that has been pushed over the past few years, mostly by pseudoscience and overly creative hollywood directors, that humans only use 10% to 15% of our brains. This myth came from studies that sensationalizing journalists misread. When researchers started connecting electroencephalogram (EEG) sensors to the brain and measuring which parts of the brain light up when individuals do certain things, what was noticed, and quite logically, is that at any one point only about 10% to 15% of the brain was active. This was immediately jumped on by these journalists to construe that we only ever used this small percentage of our brains. But what they failed to recognize, probably intentionally, was that over the course of normal brain function, as we do different things we DO use all of our brain. We use different parts of our brains for different things. Some parts are used when reading and others when driving a car, we don't use all of our brain, all at once. It's as if they read that Chefs only use 10% of their ingredients in each meal and came up with the conclusion that chefs were only achieving 10% of their potential. They are essentially saying “Imagine how amazing the chefs food would be if they used 100% of their ingredients…” Can you imagine a mushroom soup that also included coffee, peanut butter, shrimps, mint, olives, watermelon and dark chocolate? We don't have a spare 80% capacity that we just need to figure out how to tap into. Our brains have evolved the capacity to accomplish what they need to accomplish, and for 2.5 million years, it did not need to accomplish much!
But that does not mean we could not hack our brains and find some useful approaches to boost some aspect of it. This is what we started to discover thousands of years ago, we started to discover methods we could use to creatively boost our mental capacity. Similarly to how we discovered we could boost our physical ability by employing the muscle power of other animals to plow our fields.
It looks like that about 70,000 years ago we started to discover ways we could boost our mental capacities, which resulted in the Cognitive revolution. During this time, we invented the cooking of food with fire which released more usable calories, more usable calories would have resulted in more usable time to develop more sophisticated language, cultures and societies. More sophisticated language would have helped more complex ides being generated. I don't pretend to know the full story, and the full story is not relevant here, but a part of it is: Around that time, humans started agriculture, domesticating animals, forming cultures and larger social groups. We also started to specialize, some of us became dedicated hunters, others took care of domesticated animals, and agriculture and yet others moved into healing, child care and governance. Now within a lifetime you could no longer learn and know all there was to learn and know. From here on our perceived ignorance started to increase rapidly. In order to function, we needed to create a basic level of trust, community and knowledge, which could form a framework upon which we could specialize and still retain the ability to communicate and interact with other people who are specialized in quite different areas.
Seventy thousand years ago, when we started building larger communities and started to specialize, it forced humans to become more cooperative. And even though we could not individually learn all there was to learn, we figured out a few tricks, a few mental hacks that even though they did not increase our mental capacity on an individual level, did on a communal level. If we could no longer learn and know all there is to learn and know, perhaps we could share it across many individuals, and create a simple framework within which we could leverage other people's knowledge as if it were our own. We could comfortably operate in an environment where our ignorance increased because we offloaded that ignorance to someone else. That way we could each specialize, and as a collective, a collective intelligence could emerge, even though no one individual knew and directed everything. Now, if I were a farmer, I could give some of my crops to the hunter, and they would give me some of their meat. I no longer needed to know everything there was to know about hunting, I now only needed to know what the hunter wanted (their input), a basic understanding of what they did (the process) and what the hunter provided in return (the output). I hope this input, process, output is reminding you of a common theme here.
lego brick by Lluisa Iborra from the Noun Project
Now this simple hack, of sharing the burden of knowledge among a small community where everyone knows each other and what their inputs and outputs are was successful, but only for small communities. This hack became unfeasible for larger communities, and relates to humans' limited capacity to only be able to maintain stable social relationships with at maximum 150 other people, called the Dunbar’s number. This lack of mental capacity limited the success of these communities, and their collective intelligence. And so for the next 20 thousand years we started to explore ways of hacking our mental shortcomings again when we started building larger communities.
And this is when we discovered another series of powerful hacks, we could create extra-realities that are not bound to what we can see, feel and experience, but rather an extra-reality we simply choose to believe in. A simple contemporary example is our hack to create an extra-reality for currency. Now instead of us carrying bushels of wheat, goats, fish or gold, to purchase a piece of clothing from the mall, we can pay for it with a piece of paper, or more commonly, a string of zero’s and ones, that have no intrinsic value. One of the most successful shared extra-realities we’ve built which allowed for mass cooperation, was religion. Religions allowed for a whole lot of complex structures and agreements to be put in place, ones that were not coded for in our DNA, but rather ones we created. These extra-realities allowed us to hand over even more of our ignorance, no longer did we need to know everyone in our community, we could still cooperate with them knowing which extra-realities they believed in. These extra-realities, had significantly more capacity than our initial hack, that simply offloaded our ignorance to our small community of neighbors who we need to deeply know. Now instead of knowing what the inputs and outputs are of every individual we met, we could hack that requirement and simply learn what the inputs and outputs are of these extra-realities, and then as long as the person we are interacting with subscribed to one or many of the extra-realities we know about we could start to interact and collaborate. We could start to generate a collective intelligence that greatly exceeded the limitations of Dunbar's number, that historically seemed to be one of the factors that limited growth.
Now these extra-realities allowed for an increasingly complex society to be created, the more well defined the shared extra-realites were the more complex and seemingly “successful” the society could become. And all this was done without increasing the capacity of our human brains, beyond incremental improvements that resulted from more healthy living, and more efficient learning practices. We can imagine shared extra-realities being like the bricks we are building here, the more complex and well defined the bricks are, the more complex the structures we can build with them could become. We don't all need to understand what went into the design and building of a lego brick, we just need to understand what the inputs, and outputs are and if it's design fits with our goals.

Source: https://cheezburger.com/8350409984
A side point to consider is that these collective intelligent systems we were starting to build were not just limited to groups of humans. The ability to create shared extra-realities that are beyond what is physically experienced, is something that is quite unique to Humans and may be one of the contributing factors to the cognitive revolution that occurred 70 thousand years ago. Other animals don't have religions as far as we know, they don't have a monetary system where the monetary instruments don't actually have value, like we do, Although there have been some experiments that put this into question. As far as we know humans are the only animal that has accomplished this. But that is not to say other animals were not somehow also connected to this collective intelligence. They too played an important role. A prime example was the wolf, that over those 70 thousand years has become the dogs we love today. They provided our collective intelligence with information humans alone could never have perceived, like the smell of a threat 2 kilometers up wind, the speed and strategy to allow us to herd large flocks of sheep, or the added protection afforded us while we slept. Here too, all that was needed to add them to the collective intelligence was to understand their inputs and outputs. A collective intelligent network could cross species lines, and possibly even political lines… maybe.
So for the past 70 thousand years these hacks allowed us to significantly boost our mental capacity, first by offloading much of what needed to be learned to specialized experts in small communities, and later to large extra-realities within which millions and billions could operate, offloading more and more not only to other humans, but also to ideas -extra-realities- we simply made up and chose to believe in. However, even these extra-realities have their limits. Most are centrally controlled, which seriously limits their ability to scale, grow, mature and keep up with our requirements. When we first discovered Newton's theories of motion and learned that the earth was not the center of everything, it look many hundreds of years for this new “brick” of reality to be included into the extra-realities we subscribed to. Centralized control, while great at providing stability, is really poor at innovating, which I’ll go into more detail on when discussing open versus closed innovation, later in the paper.
Today, many of our extra-realities are starting to reach their capacity. The rate at which new knowledge is generated is increasing exponentially, our bricks of new understanding are rapidly being stacked on previous bricks, and it is becoming increasingly difficult to retain enough of a shared understanding to facilitate strong cooperation. Even within a singular highly specialized domain, the knowledge generated often exceeds the speed and capacity for specialists to learn and retain that information. Take specialized fields like neurology, quantum physics, computer programming and machine learning. Here, if we were to read all the latest findings within that field, by the time we finished reading about them we would have double the amount of new findings to then read about, and once we finish that, we would again have double the previously already doubled amount to read up on. The rate at which new knowledge is generated in many cases is becoming exponential. And yet we are limited by the finite capacity of our minds to learn and process that information, and the linear growth in complexity of our shared extra-realities we are using to effectively communicate and collaborate.
Even if we simply consider what information our kids should learn as a foundation, this too is increasing far quicker than we have the ability to learn. Consider how poorly the current educational system is preparing our kids for the future they will live in. When factory model schools first started, we could fit all our kids of different ages into one classroom and over a few years, teach them all they needed to know to form a foundation on which they could then operate and effectively communicate with others around them. Then as more needed to be learned to have an effective foundation we split them up into age groups and created secondary school. Then when that was no longer sufficient, we created college, then the Master degree, then the PHD, and now in some fields you need several post docs to start out. Now I do think this trend can be slowed down somewhat by offloading some to this foundational knowledge, like needing to memorise random facts and learning to drive a car, both of which are becoming redundant. But, and this is a big BUT the amount we can offload does not compare to the amount to new knowledge our kids should learn. This not only includes life skills, that are critically needed like communication, collaboration, critical thinking, creativity skills but also includes a rapidly growing amount of contemporary topics like how to manage your online persona, navigate the challenges of social media, news and political bias, broader sex and drug education, online privacy, avoiding scams, modern financial literacy excetra. The amount of foundational information needed to be learnt is itself increasing exponentially.
If we extrapolate this phenomenon, the distance between people's understanding and worldviews are only going to increase… A black mirror episode could easily be created on this phenomenon, showing two well meaning kids who grow up within two distinct groups, whos base knowledge and world views differ so profoundly, simply because they now live in a world where there is too much to know, that they both look at each other not as humans that share the same DNA but as something that's alien. We can already think of various example of this happening today.
We need to figure this out, we need to overcome this limitation to allow us to continue progress towards greater understanding, maturity, compassion and love for all humans and all life.
Therefore to conclude this chapter, I’ll describe the next few contextual challenge bricks we will use during our discussions that represent our need to create a scalable framework within which to collaborate, despite our many limitations.
![[lego brick by Lluisa Iborra from the Noun Project]](https://images.squarespace-cdn.com/content/v1/53600e19e4b0b9aa739a6514/1585946426328-9FYSQO67RGPIZ8GLW5JR/Super+Intelligence+Bricks+-+2020-04-03T164012.777.png)
[lego brick by Lluisa Iborra from the Noun Project]
Context Bricks 3 - Two sides of the same coin
Context Bricks 3 - Two sides of the same coin
Two sides of the same coin, Learning and Doing.
First, we learn how to do, then we do what we learned, increasingly these happen years apart, however, we can radically accelerate both learning and doing if they occur in parallel and in real-time.
In the next two chapters, the final two of this context building part of the paper, I’d like to focus the discussion around education -when we learn how to do the things we need to do in adulthood- and then on work -when we do what we learned how to do while in school. It seems that work and education have been designed to follow one another: for 20 years we get educated and learn things, then for 40 years we get to work and do things, followed by 20 years of complaining about the many things we could have learned or done. In reality learning and doing are two sides of the same coin, a coin we could flip between multiple times throughout our lives, even multiple times a day. While the next two chapters focus the discussion on why education and work are ill-designed for collective intelligence, an underlying theme that will be picked up on later is that this two-sided coin, if redesigned, could allow us all to flip between these two sides seamlessly at any stage in life, even multiple times a day. Why can't my 5-year-old daughter, do real work like designing and building an exoskeleton that helps paralyzed people move? Why can't a 60-year-old learn to become a game developer after spending a lifetime as a plumber? Learning and doing are two sides of the same coin, we should not think of them as separate, we should not limit them to certain ages, they are one and the same. They are continuous.
Consider how we learn and do things before and after we leave school. As kids before we go to school, we learn by doing, by experimenting, by playing, by arguing, by exploring. Then after we finish school, and if we are lucky enough to work in an empowering job, how is it that we learn? Well, we learn the same way, for example, when I suddenly needed to implement a new machine-learning algorithm, I learned by doing, by experimenting with examples that others provided, by playing around with other similar solutions, by arguing with my fellow team members, by exploring random projects. The way we learn before and after finishing school follows a similar approach, And yet, why is schooling, the time we are supposed to be learning the most structured so fundamentally different? This structure is a considerable bottleneck and friction that slows down collective intelligence almost to a halt, to time scales years in length. In the next few chapters, we will start to look at ways we can reduce these time scales to hours and minutes, the timescales needed to spark Super Collective Intelligence.

Context Bricks 4 - Education, not setup for collective intelligence
Context Bricks 4 - Education, not setup for collective intelligence
Why is education, the way we learn things, currently not setup for collective intelligence.
Our educational systems are ill-designed to support collective intelligence and support the development of solutions to the context bricks already discussed above. Here I’ll discuss some reasons why, namely the slow speed at which new learning is propagated, the disconnect between learning and doing, and the inefficient way we teach through producing one-size-fits-all pathways. All of which limit the emergence of collective intelligence.
To illustrate, let's first talk about foundational education, this is what we learn in school, colleges, and universities before we enter the workforce. I must admit that I’ve been utterly frustrated with this part of education since I entered into it at the age of 6, However, I’ve ironically seen my career path move closer and closer to this domain, and now I spend most of my time here. This foundational education model has seen very little change since the factory model of education was invented about 150 years ago, at the birth of the industrial revolution. Sure, the content of what is being taught has expanded, and the methods have improved, but the underlying structure of it, the foundation, has remained the same:
Let’s get a bunch of kids, group them by year,
Assume they are similar,
Process them through an assembly line process, removing any imperfections like their differences.
And send them into the factory, that is the world, assuming that the education we designed several years ago is still relevant today.
And only once they finish 20 years of this, will they be accepted in the real-world where “real work” is done.
Now we have probably all heard the same frustrations from hundreds of educators, parents, and kids, but how does this relate to collective intelligence and emergent learning? The first issue is the speed at which new knowledge can propagate through the network. Currently, it takes several years for new knowledge to be incorporated into the network. As an example, when science or business discovers some new concept, it first gets worked on and refined within closed siloes, then limited information is published if we are lucky, and several years later once patents have expired, it gets incorporated into a new curriculum before its more widely propagated. We need this to happen in real-time for super collective intelligence to emerge. New discoveries, methods, science, technology and knowledge should seamlessly be translated to new learning in real-time. Currently, our systems, education and industry are not designed to handle this, but with some small, yet fundamental tweaks, our systems could be structured in such a way that learning and doing are built hand in hand, where work and education are so closely aligned, that their distinctions become almost irrelevant, and we will discuss this later in the paper. But before we go there, let's talk about some other reasons education today is not well designed to foster collective intelligence. Let's talk about learning paths.
Education at its smallest component is about teaching singular granular concepts, one at a time, and as more concepts are learned, stacking them together, as you would with lego bricks, to create more and more complex concepts that can be understood and learned. But we can't just learn a whole bunch of random concepts, these don't stick in our memory, and so over the years we have developed methods to help them stick. As Humans, we battle to retain more than a few random concepts in memory if they are not somehow connected together through context and narrative. Our brains are physically structured in pathways of neurons, called neural pathways. We don't have random access memory like computers do, we have pathway accessed memory. This is why we love stories and relate far better to stories than random facts that have no context or relevance. Even people who have a seemingly photographic memory and can retain random facts, like Ken Jennings, the world champion of random facts, memorizes these facts by creating pathways to them in his mind. If he needs to recall some random fact about Indian history, he travels down an imagined hallway in his mental castle, turns right at the kitchen, opens up the pantry of history, finds the section that relates to India, in this case, the spices section, then goes ahead and searches for the right combination of spices, tastes and smells that then trigger the correct memory of the random fact he needs to recall. Another example is how Daniel Tammet, can recall the first twenty-two thousand numbers of Pi from memory. He does this by converting each number into a color, smell, sound, and feeling, and then when he recalls the number, he simply recalls the "song" that is created by the colors, sounds and feelings. Daniel did not memorize the numbers, he has memorized a personal story, a song that represents Pi. Notice how personal Ken’s and Daniel’s stories are. They would not be able to recall as much as they can if they were to recite someone else's story. The more personally relevant the story, the more we can retain and understand. The more we can retain and understand, the more we can share.Teaching concepts within educational stories, therefore, makes a lot of sense. That is why creating courses that go through a sequence of concepts within a narrative framework, works far better than simply learning random concepts. So we got that part right, we create educational stories, but we did not get the personal part right. Remember, it was Ken and Daniel that created their own story which allowed them to succeed so well, it was not a story created by someone else that they used. Consider how few students get top marks and learn 100% of what there is to learn in the educational stories we produce for them. The stories we present to learners are so generalized that they have little relevant context for the learner to internalize. If you were to test the same students, even top-scoring students, a year after they finished their qualification, most would have forgotten what they have learned, because so very little has been internalized. It's as if we forced Ken Jennings to memorize our version of a castle instead of allowing him to create and use his own, Or that we removed the sounds, smells, feelings from Daniel Tammet's story, and instead got him to memorize just the numbers of PI.
We can think of the educational stories we currently create, like a lego model and the individual concepts being taught in them as lego bricks. But unlike lego that was actually designed to be broken apart, rebuilt, repurposed, redesigned an infinite number of ways, our educational stories have been glued together into impersonal models. We can actually use Lego and the Lego movie as a great analogy here. In the Lego movie, the dad "Lord Business" tries to glue all the Lego pieces together so that they retain their "designed" shape. Lord Business believes that the best way to build Lego models are exactly how they were presented by the "expert" designers at Lego. Now, Lego models were not designed to be used in that way. While it does help to sell bricks by presenting them in suggested models, ultimately Lego wants the bricks to be used to create something personally relevant to the person who plays with it. This actually makes financial sense for them. If a child does create something personal with the bricks, if they recombine them, design and build something personally, as opposed to simply building the pre-designed models once, then the retention and engagement the child has with those lego bricks is orders of magnitude higher than for kids who simply build the model once. If Lego can get a child to personally experience the joy of designing, building and playing with the bricks to create their own personal imagined stories in play, then those memories and feelings are imprinted deeply into the child's memory, this intern increases the lifetime value of that customer (the child) as they continue to purchase lego, for themselves and their kids when they grow up. If however the child simply builds the model once and does not create their own personal connection then, just like most other toys, they are quickly forgotten about and no deeply imprinted connection is made. To make the same revenue in that situation lego would need to create mass-produced build-once disposable-models and hope they sell enough of those to equal the longer lifetime value of more committed customers.
![[Source: Lego Movie]](https://images.squarespace-cdn.com/content/v1/53600e19e4b0b9aa739a6514/1585943779038-EUW8JYA7ARSXNY0PH7V3/sCKMixE.gif)
[Source: Lego Movie]
Will Lego focus on impactful deeper personal experiences, or more volume but throwaway experiences? As I see it, Lego has infinite possibilities, but only if you break the mold! Similarly, we have the same choice in education: empower learners to build their own deep and personal learning stories, or continue to mass-produce, one-size-fits-all pathways.
Now there is a lot more we can do to fix education, and I’ve written and spoken about that in detail elsewhere, but because this post is focused on collective intelligence, I will only briefly mention some of these points here that are still relevant:
There is another reason personal learning paths compared to one-size-fits-all paths are so much more valuable and that is that they can tap into the intrinsic motivation of the learner far more easily. In one project I was running in East Africa - You can learn more about it here, we were trying to solve the problem of motivating kids to learn on their own when they don't have access to teachers, schools or even parents that would encourage them to do so. We were building a digital tool that could rapidly be deployed to the hundreds of millions of kids in this situation but we needed to figure out this motivation challenge. We tried game mechanics, providing kids various extrinsic rewards, and while this worked very well for the first few hours and days, their engagement quickly diminished. We needed to find ways we could better tap into their intrinsic motivations, which is when we started to tie intrinsic goals to their learning. Now instead of trying to motivate a child to learn how to read, write and do math, which by themselves had no tangible relevance to any of their intrinsic motivations, we provided them tools to map out how to get to where they wanted to go. Now suddenly their passion to become a Nurse or bicycle mechanic translated into a personal path of learning that was relevant to their goals -I go into detail on how we did this, first in the Learning Map chapter, and later in some of the solution bricks. But for now, the point that is relevant here is that, intrinsic motivation, is a key component to learning, contributing and ultimately the motivation to contribute to a collective intelligence.
Finally, and I won't spend more than one sentence on this point, because so much has already been written about it. Is that education as we know it currently does not empower kids with various skills and knowledge they need today, like creativity, communication, collaboration, critical thinking...
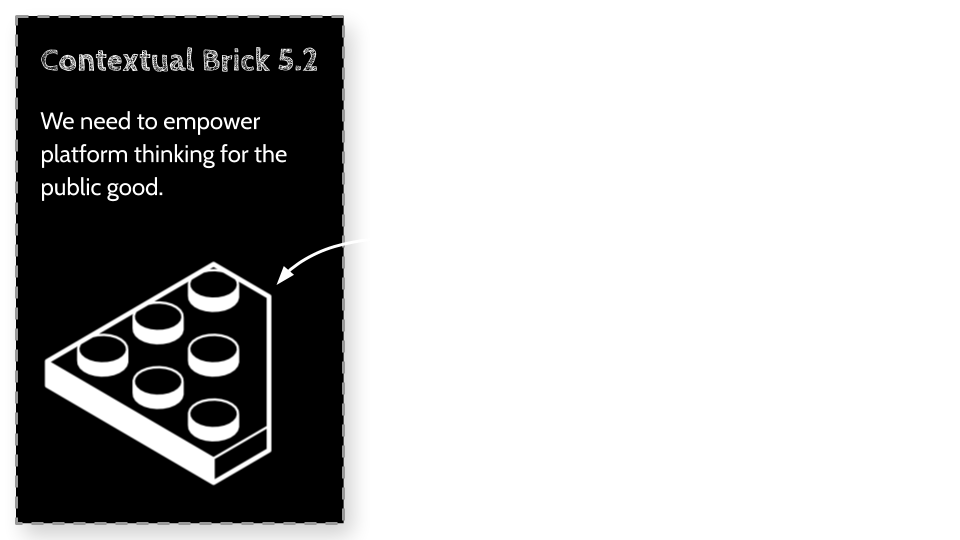
lego brick by Lluisa Iborra from the Noun ProjectContext Bricks 5 - Companies, not currently setup for collective intelligence.
Context Bricks 5 - Companies, not currently setup for collective intelligence.
Why are companies, the way we do things, not currently setup for collective intelligence.
Much like our educational models are ill-designed to support collective intelligence, so too are our companies because of how they are structured, grow, innovate and only share the value they generate with a small number of founders and big investors. To describe this, let’s consider companies to be a collection of bricks. Much like we considered educational pathways to be a collection of concept bricks stacked together in a linear path, let’s consider companies to be a collection of functional, process, organizational and technological bricks. that when stacked together create a company. You may have a business model brick, a go-to market brick, and sales strategy brick, a few product bricks and some business operations bricks...
Now in most organizations these bricks are not only glued together, they are welded, bolted and jammed so closely together they are often seen as a whole instead of a stack of bricks. But why is this? Traditionally, when you choose to solve some problem you would start some type of entity, probably a company, where you could then raise some resources, hire some people and then solve whatever is was you wanted to solve. Building such a structure was required because you needed to make sure you could coordinate all the separate pieces of the company to do what they needed to do. You would spend a lot of effort creating a management framework, and a whole lot of processes that tie these separate parts closely together, trying to make the transaction costs [the costs of handing a piece of work from one part to another part of the company] as small as possible. For hundreds of years creating such a structure was the most efficient way to accomplish this, and over these years we have developed robust mechanisms in support of it, like management frameworks, legal structure, process structure and physical structure; explained really well by Clay Shirky in his 2005 TED talk, Institutions vs. Collaboration. However, these robust structures, and a false belief that creating these structures will remain the best way to solve problems, has resulted in them trading the benefits of modularity, for the illusionary efficiency of gluing things together. This calculation may have made sense for many hundreds of years, but no longer, or as Clay Shirky describes it “We have lived in this world where little things are done for love and big things for money. Now we have Wikipedia. Suddenly big things can be done for love.”
There is a critical limitation in traditionally siloed companies and how they innovate: radical innovation generally happens only once within their closed systems, at the beginning of the venture or new product. After that initial radical innovation is implemented, the natural state of the system is to protect that innovation and from that moment focus on optimization. This optimization strategy is a successful approach to the extent that it maximizes the value of that initial innovation for the founders and big investors who retain most of the equity. However, it's not such a successful approach for the vast majority of contributors that actually make the innovation work and own little to none of the equity. Therefore, we see time and time again radical innovation generating a successful company, that then monopolizes that level of innovation, shifts to optimization and extracts value for the few instead of innovating further for the benefit of the many. One of my favorite books that presents research on this in extraordinary detail is The Master Switch by Prof. Tim Wu. Here he describes how some of the most innovative companies of the past 100 years fall into this trap, stifle innovation and get stuck, or as he says “if everything is entrusted to a single mind, its inevitable subjective distortions will distort, if not altogether disable, the innovation process.”
It is this getting stuck that limits the shelf-life of this optimization strategy. We can illustrate this by thinking of innovation as a point on a chart but where we only have limited visibility, a few steps to either direction (see chart). When we develop a successful innovation, we have somehow found an elevation on this chart, but because we don't have a lot of visibility to either side, from that moment onwards, we play it safe and take small incremental steps. We A/B test our product or solution, we run surveys and we focus on safe small steps forward. This is until we find the point on which any further innovation seems to make things less effective. This is a point in mathematics called a local maximum. It's the maximum height of the chart within a small local area.
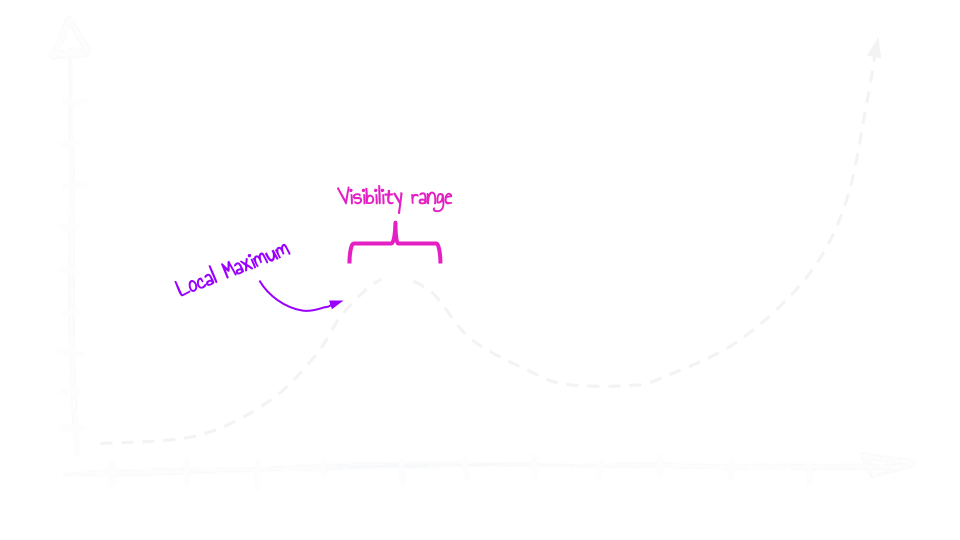
Once a company reaches this point, it seems that any further innovation makes them less effective, and so they focus on optimization instead. Optimization, in these cases, further glues and solidifies the separate bricks together to make them more “efficient”. And while this optimization phase can still reap a lot more value, eventually there will be diminishing returns, as the resources required to optimize further outweigh the value that optimization will provide. A good example is Education, and Healthcare. On their current local maximums, their focus on optimization is now at a stage that the amount of return of investment per dollar spent on optimization is in many cases negative. Education and healthcare costs in the USA continue to rise, yet outcomes continue to fall. The only hope for more effective solutions is radical innovation. But at that stage, there is no easy way out for these companies, especially if they have glued their bricks together. They must either adopt a disruptive innovation or decide to let the venture run its course and close in bankruptcy after it has lost its value through obsolescence.
Let’s consider a real world example, Kodak. They produced a radical innovation in film based photography, and then spent decades optimizing their innovation. They had an exceptional run on their local maximum extracting a ton of value, however, their business model and shareholders did not allow them to radically innovate any solutions that would threaten what they had built. Even though Kodak were the ones who invented the digital camera, they could not get themselves to disrupt their existing model. Kodak went bankrupt when their market moved off of their local maximum to other innovations that generated far more value. In these companies, the bricks that make their business work are glued together, through internal processes that initially seem more efficient, but in the long term limit innovation. In the Kodak example, their marketing, finance, investments, technology, and product bricks were so closely glued together that it was impossible for them to even experiment with other bricks without causing their whole structure to potentially collapse. Consider what could have happened, if they intentionally kept the bricks that made up their business modular, so that they could easily experiment with replacing some parts with newly developed and updated bricks. They could even have quickly setup completely separate copies of their business replacing a few bricks here and there and creating multiple versions that tested the market. They certainly had the talent and market dominance to do so. Instead a 15 person startup, Instagram, became a successful billion dollar digital photography business with a market cap that now far exceeds Kodak at its peak, while Kodak filed for bankruptcy. Now this is not to say that the optimization strategy, and maximizing efficiency on a local maximum is a bad strategy. After all you would not want some of your governmental services like infrastructure maintenance to continually be disrupted. What I am highlighting here is the challenge that is presented by these traditional structures, and how, if what I described in the first few bricks is accurate and we do need to rapidly innovate and reinvent almost everything we do, then this challenge is one we need to tackle head on.
In the Foundational bricks chapter, when discussing the Doing Map, I describe an approach where if we redesign the way we build companies, products and innovate, we can create a structure that will allow for optimization and a structure that will allow for radical innovation to work in partnership, in a positive sum ecosystem. Imagine a company landing on a local maximum, focusing on optimization while allowing a smaller part of its structure to continue radically innovating, and when feasible merge any innovations into its main operation when it can minimize any disruption. In this positive sum ecosystem companies can enjoy the best of both worlds, however these companies will not look like any of the companies we see today, we may need to come up with a new way of describing them.
However, before we get there, there are a few more contextual challenge bricks I’d like to discuss.
Platform thinking as a public good
If we consider all the challenges in the world, a majority of them don't get addressed, because there is simply no sustainable business model that would fund the work needed to solve them, called the 80/20 rule, or Pareto principle. But that is only true within the context of our current economic models, something I discuss in a later Innovation market brick. For now I want us to recognize that a large portion of challenges require a different approach to solving them. They require platform thinking as a public good.
As an example, we can compare Microsoft windows and Linux and how the organizations around them operate differently to address the feature and bug fixes their products need. With Microsoft, it is a centralized system that determines which features and bugs to build/fix. This takes the form of a power law distribution where Microsoft focuses on the top 20% of features or bugs, as they would produce 80% of the value. There is hardly ever a business case that would justify them tackling something that is in the bottom 80% where only 20% of a value is expected. However, with an open project like Linux, the community can effectively tackle the other 80% of the features and bugs if they so wish Or as Clay Shirky describes in his Institutions vs. collaboration work: “...This kind of value is unreachable in classical institutional frameworks…” . It is often that Linux gets a contribution from someone, simply because that individual saw a problem they cared about and felt compelled to fix. This person did not need to have a formal relationship with Linux, nor did they need their permission or somehow convince Linux through a business modeling exercise that it would justify the development of that solution according to some 80/20 rule. This self-selecting approach within open systems is highly effective, especially as the contribution then becomes open and available for all to leverage and implement.
Rapid 1000X innovation is possible
Another key reason businesses tend to glue their bricks together is to retain strong centralized control, which allows a small minority to extract maximum value. Within these traditional organizational structures, the value that is generated is generally only shared with a very small proportion of those that contributed to its generation, those that happen to have the most equity in the company. If we want to maximize the rate of innovation, we need to maximize the incentives for all those who contribute not just those at the top.
Consider an alternative. Imagine that a business model brick, marketing strategy brick, various product bricks, goto market bricks and all the other bricks that make up a company were modular and openly available for anyone to leverage in return for a proportional stake in the businesses that use it. Instead of the bricks being developed by siloed teams stuck within a closed business, they could be developed by the best minds from around the world. These best minds, could be working on bricks across the power law distribution described in the previous paragraph. A decentralized group may be working on the perfect marketing strategy brick for some niche use case, another group may be working on a water desalination brick. Here a new venture could rapidly select from a library of bricks, combine them like you would Lego and have a portion of the value generated by the business be equitably shared to all those who contribute to any bricks used. We can even imagine companies being rapidly generated autonomously to accomplish a temporary local need, like a disaster relief effort, dissolving a few days or weeks later when the need dissipates. I will go into detail later of how this is designed to work, but for now just consider the differences between this described open structure and traditional closed structures.
To help us consider this comparison, let's look at a similar example of open innovation in action, using bacteria. Before watching this quick 2 minute video, understand that bacteria share genetic information openly, similar to how I quickly described it in the above paragraph. If one bacteria figures out a solution to a challenge, in this example overcoming antibiotics, they openly share that genetic mutation. The bricks that make up bacteria DNA are not glued together and inaccessible to others, instead they are easily shared and incorporated into other bacteria.

We can think of the bacteria that gets stuck on the outer edges as businesses that get stuck on their local maximum and are limited to only be able to innovate at a linier pace for risk of disrupting their existing business models. On the other hand, the bacteria that is growing towards the center are those that can innovate to achieve 10X, 100X then 1000X the original effectiveness, which is itself an exponential rate of innovation. This is the rate of innovation we need in the real world, and here, in bacteria, is one example of how this rate is possible. Here we see an example of what companies who embrace open innovation can accomplish.
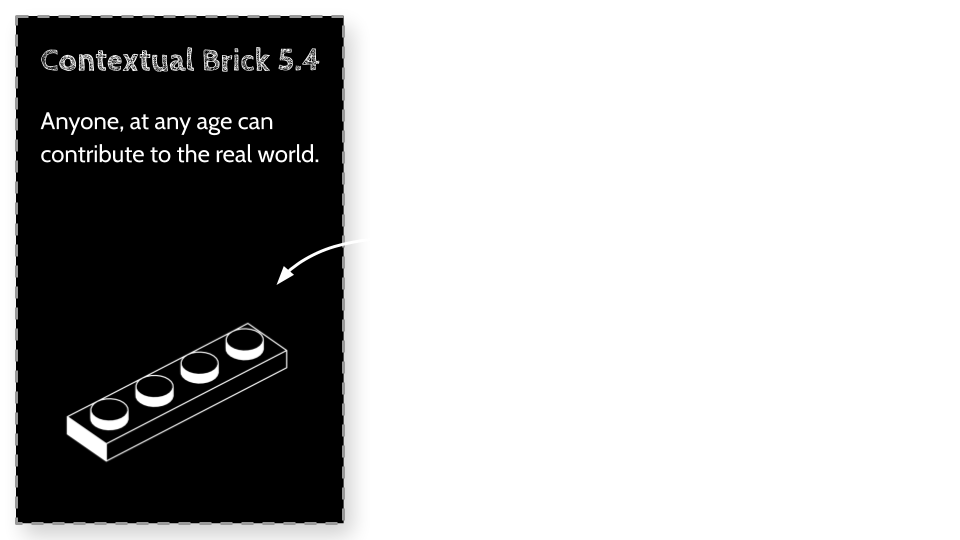
Important side note: Recognize that as we have been speaking about companies, and contributors to those companies, I don't want you to think of the form they take currently. In all of this, I want you to take a step back, come down to first principles and consider not the form we currently have, but the function we need. We need children to learn real-world skills, if they currently feel disillusioned with their education and want to act to make the world a better place, then that function is something we should design any solutions to also fulfill. Why should children not be allowed to contribute to the real world, why should their putting to practice the theory they learn not be immediate.
To end this chapter, let’s distill what's discussed above into some contextual bricks, that we will then build upon.

lego brick by Lluisa Iborra from the Noun ProjectFoundational Bricks
Foundational Bricks
The Terrain, reasoning from first principles.
The contextual bricks described above now form the terrain on which we need to build foundations. These are some of the core first principles I’ve considered when formulating what we could potentially do. The challenge is to now forget the Form of other solutions that may already be in place, and focus on the Function that is required to solve a particular challenge. Especially when considering Context brick 1.1, where we discussed that we need to rethink how the world does almost everything we do. If that's really what is needed, then following the form of existing solutions will not work. We need to develop new forms from scratch, choosing to focus on the function rather than believing all we should do is improve the form of what is already available. Our aim should not be to continue building the tower of pisa, but a new tower for the future. And that’s what the foundational bricks now try to do -forget all that came before and ask the question, If we could start from scratch with the benefit of all we know, what could we do?

lego brick by Lluisa Iborra from the Noun Project
Foundational Bricks:
So now that we have discussed the context and created the terrain on top of which any foundation should be built lets start discussing some of the foundational bricks we should place. This is where we will start stacking bricks on top of each other. If you recall, each brick has an input and an output, and the output of one should fit the input of the other for it to be able to be stacked on top of. I’ll continue to use Lego bricks as a simplified analogy, and to illustrate the modularity of what we are doing. Keep in mind that just like I mentioned at the start of the context section, this process we are going through to create these bricks is in itself an example of how collective intelligence can emerge. By now this analogy should feel like something out of the movie Inception, where we are using bricks to build bricks to build bricks…
Foundational Bricks - The Learning Map
Foundational Bricks - The Learning Map
The Learning Map
This learning map brick is designed to be built on top of and provide a foundational solution to the following contextual bricks:
lego brick by Lluisa Iborra from the Noun Project
Important: notice what is not included in the above. There is no mention of having educational pathways designed and run by institutions, there is no mention that these pathways should be taught by anyone in particular, there is no mention that these pathways should be accredited by anyone in particular… Let us intentionally not think about how we solved this previously. We need to stick to first principles. This will help prevent us from starting to think about previous forms (what we already have in place) rather than about function (what are the fundamental needs here).
The back story:
Ten years ago, with the birth of my daughter, I launched an ambitious project, it was called the moonshot education project. The goal was to develop a tool that could empower the more than 250 million kids who would never have the opportunity to go to school to be empowered to take their learning into their own hands as self-directed learners and then empower them to propagate that learning throughout their community through peer-to-peer learning. It was an audacious project, but one I believed was possible, because this was the way I had learned. We were developing this tool for kids in rural areas, refugee camps, disaster areas and for kids in gender-stratified societies where girls cannot go to school. Here, they would not have teachers, many would not even have parents who would encourage them to learn and there would be very few extrinsic motivators to get them to learn. So the question was how could we tap into their intrinsic motivations instead. It was almost impossible for us to get them to spend more than a few hours learning how to read and write. Their engagement quickly fell off, even when game mechanics were included to try to provide them some type of reward for learning. Game mechanics were able to increase engagement considerably, initially, but soon fell off as these rewards had little intrinsic value. Learning about sounds, numbers, words, songs and sentence structures was not something any of the kids were intrinsically motivated to do for much more than a few hours, or if they were bored. But that was not what we were aiming for, we did not simply want to create something that was better than absolute boredom, we wanted to create something that would inspire, empower, engage their innate curiosity and spark their passion. So how could we motivate kids to learn through a digital tool, where we could not rely on extrinsic motivators like teachers or even parents. How could we tap into their intrinsic motivations?
Kids want to change their world, they want to have an impact
“How do I become a nurse”, “how do I start a business”, “how do I build a water purifier”, “how do I prevent the spread of malaria”, “how do I become a bicycle mechanic”, “how do I fix the electrical panel that was destroyed in a storm”. There was a group of kids, larger than we anticipated, whose questions were quite deep, focused on their worlds and the impact they wanted to achieve. These were the types of questions the kids were asking, these were the types of questions the kids were self-motivated to find the answers to. This is what was relevant to them, this is what they wanted to learn. Not the bullshit reading and writing apps we initially started with, the stuff you find in most educational apps for kids. I recalled that this was also what motivated me to learn as a kid, and it was the reason why I skipped most of school and learnt instead through self-directed learning. But unlike these kids, I had some advantages. Even though I grew up in Africa like they were, I had the benefit of an internet connection, a general understanding of what was out there to learn about, and parents who were not very observant as to my schooling and therefore the freedom to do what I wanted. Now I did struggle to read, and I still do today, but you can battle through that if what you are trying to learn is something you are really passionate to learn about. So what if we helped kids answer their deeply meaningful relevant and personal questions, and helped them map out all they needed to learn to get them from where they are to where the answers of their questions would take them. That's when we started to work on building a Learning map.
What could a learning map be?
To describe the learning map let us first deconstruct learning into its constituent parts, from here, we can use first principles and try to build a solution that can achieve the required output. Let me introduce some terms I’d like to use to discuss this: Content, Nodes and Paths
Content is packaged information that we can learn from. It could be digital, like videos, pdf’s, assessments, text, audio, web pages, games, music, code, but it could also be physical items, like people, places, objects and equipment.
Nodes are a concept that can be learned for example; single digit addition, the concept of nouns, the concept of what DNA is, or how to beat-match a song. Every concept that can be learned can be considered a node. Now we may not all agree what nodes we should have and initially there may be a lot of duplicates, but this is ok, later on i’ll describe how we can deal with that, similar to how nature deals with duplicates, or how wikipedia deals with duplicates. Consensus can be reached as an emergent phenomenon, if the correct framework is put in place. When considering what a Node is, a good rule of thumb would be to make sure that it can be described in 2 to 10 minutes. For example, Let’s say we are building a number of nodes to describe how to ride a bike. Showing foot placement on the pedal, which could be described in a few seconds, is too small to be considered to be a node, and should be combined with more information. However a 45 minute lecture on bike riding that includes information on the history of the bike and bike maintenance, should be broken up into smaller nodes. Once we have a node defined, they can then be tagged with one or multiple pieces of content. For example The node for DNA could contain a video lecture from stanford, a published paper by a PHD candidate, some sample DNA sequences, links to DNA experts, the equipment needed to view and manipulate DNA, news articles or wiki pages describing how it was discovered, labs that work with DNA, products that include DNA, etcetera. What is key is, that the nodes themselves are singular, stand-alone containers that represent a singular concept that is taught. Then tagged to that is any number of pieces of content as defined above. You can also think of each node as a saved google search for content. This “search result” displays all content that is tagged to the node, and just like a Google search these could be personalized, ranked, filtered by language, preferences or whatever else is required. As shown in the below example taken from our work on the Moonshot Education Project.
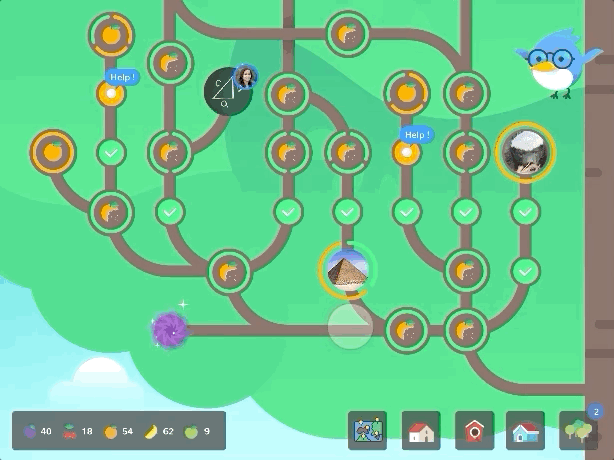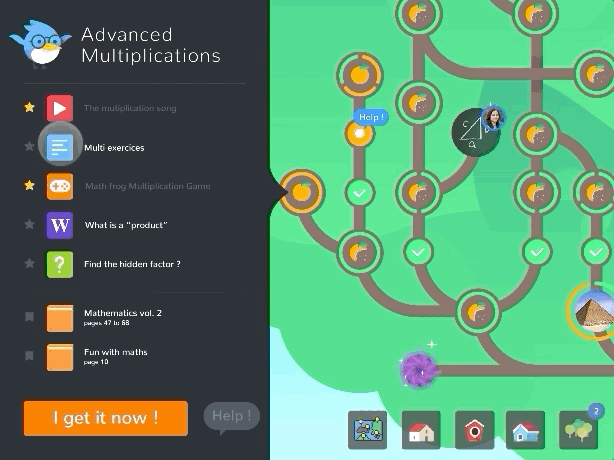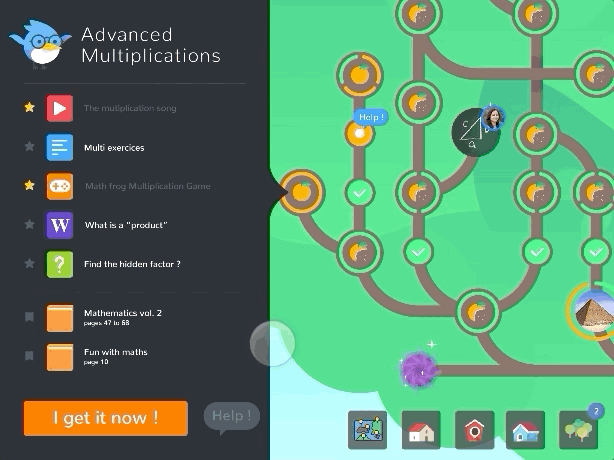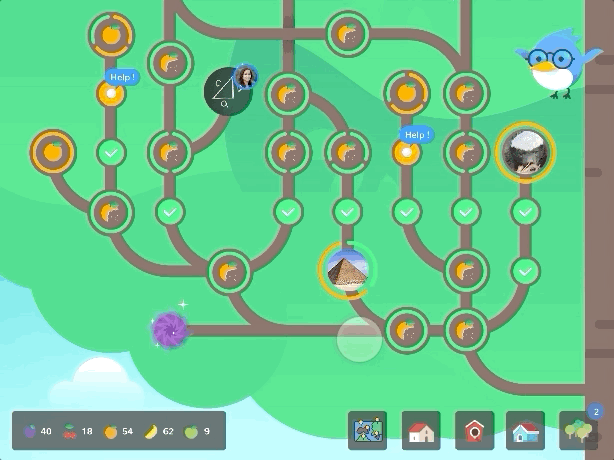
While the content that is tagged to a node is relatively fluid, the description of the node is not, much like a wikipedia page, where the page structure, the ontology of wikipedia, is quite robust but the content on each page could be quite fluid until a strong consensus has been reached. And much like a wikipedia page we can leverage similar mechanisms to form consensus about the node descriptions and their content. Another way of thinking of nodes is to think of them as concepts in frameworks like the US common core educational standards, or various other educational frameworks, however we cannot assume that any of these are robust, as that needs to be accomplished later by the network. Consensus will be an emergent phenomenon, not dictated by a centralized power. And here we need to learn some lessons from Wikipedia, where consensus, while it is an emergent phenomenon, is created by a small seemingly homogenous group of mostly old white men. We need a more holistic consensus to be reached.
Paths are a collection of nodes, with directional weighted connections that tie these nodes together. Paths are what learners are most familiar with and are how curriculum, courses, textbooks, lectures and almost all LMS's (learning management systems) structure learning. Paths could include branching logic, optional side paths or built circularly. Paths also add additional metadata to the nodes they include, similar to how a course, textbook or lecture usually also includes some narrative around the teaching of the concepts within it. You can imagine a path built by Harvard, pre-filtering the content tagged to nodes based on the content they prefer to show learners. Or you can imagine a path built with conditional logic requiring a learner to complete a particular node before access to following nodes are granted. This therefore enables paths to include all the functionality traditional institutions and models currently have, without losing any of their dynamic potential.
With these three core components we can build both traditional learning paths and models, but could also enable the creation of dynamic paths to be created.
A Graph Database, a Google map.
So we can consider the Learning Map to be a graph database of nodes, seeded with the links created by paths and additional links created through machine learning and user data. With this structure, we can produce Dynamic Path Creation by doing path analysis between the nodes the user has already completed and the nodes the user wants to get to.
For example I could search for “How do I sequence DNA” and because the platform will know which nodes I have already completed and the node I wish to get to, the platform can show me a google maps type learning map of all the possible nodes and paths that lie between where I am and where I want to get to. If there happens to be pre-designed paths somewhere in between then the platform can recommend that to me, but the platform can also generate custom dynamic paths based on my preferences and the dynamically generated weights of the links between nodes (nodes representing addresses in this analogy).
Consider Google maps:

If you wanted to get to the Frisbee Hill from the Empire State building, Google maps may suggest that for parts of the trips you use mass transport: It may suggest you use the B train to get from 34th street station to 72 Street station -we can think of these as mass produced, one-size-fits-all pathways as discussed in the previous chapters, but these only take you part of the way. You don't only want to get from 34th street to 72nd street. Firstly, You are not yet anywhere close to 34th street station, so first, Maps recommends a custom path to get you there, and because you also don't simply want to get to 72nd street, maps creates another custom path from there to Frisbee Hill. But then let’s also consider real-life. You probably want to hop off a few stops before 72 Street, because the B train sucks, and so dynamically google generates a new path from where you hop off. The same is true with the learning map, maybe the pre-designed paths that schools or institutions design suck, so we should empower learners who do want to hop off that path and find a better way to get to where they want to go. In Google Maps, road traffic conditions, motorist travel patterns and road speed limits affect the paths that are recommended, and two users may see different recommended routes getting them from point A to point B because they search at different times or they may have different preferences. With the learning map we use a similar mechanism which is generated through the weights of the links between nodes and the users themselves.
How the learning map is created:
There are a number of ways we can create the learning map, here I’ll describe a few approaches we are taking or have experimented with, all of which can be used in parallel and as complementary approaches.
Approach 1 - Building from Existing Material
One approach we can use to build this Learning Map is to build it from deconstructing existing courses, curricula, online programs, textbooks, lectures or any other pre-packaged learning paths. In this method, we leverage the expertise of educationalists who have created courses, online learning programs, youtube videos or lectures to define not only the nodes, but also the links between them. We then use this as a “seed” to create the start of the map. Here, in this illustrated example I’ll describe this approach.
Step 1 - Identify material.
We identify existing material that can be deconstructed into learning paths, nodes and content.
Step 2 - Deconstruction
First we extract the concepts being taught and convert them into Nodes and then extract the content and tag them to those nodes.
Step 3 - Define Paths
Then we join nodes to create learning paths based on the order in which they were presented in the contend we just deconstructed.
Step 4 - Estimate effort
Each node has an estimate on how much time it would take to learn the concept within it. And I understand that this is different for everyone, but here, we just need to seed the map with some best guess data from which an initial structure can be created. This is an important step as it is used to determine the node's dynamic position on the learning map based on the lense through which it is viewed, as explained later.
Step 5 - Networking
We extract additional nodes from the course that are referenced but not taught. If these referenced nodes are already created on the map then we create a link, and if they are not created, we create a placeholder for them. These referenced nodes become additional nodes not directly taught in this learning path but linked to it, through lesser weighted links, as described later.
Step 6 - Link Keywords
Keywords in the node are used to link to other nodes that also include those keywords. The relevance probability can be calculated through using text analysis algorithms like word2vec, LDA, LDA2vec, ML and maps like DBpedia, weLEARN excetra. Weight of these links are proportional to their relevance probability.
Step 7 - Path Map Networking
Now that we have the nodes, and links extracted, we link the extracted nodes to every other node where they are mentioned. This creates the map of the path we deconstructed.
Step 8 - Weighted Link Networking
Now that we have a map of nodes all linked up, we add weights to the links based on relevancy. These weights are just “seeds”.
Links that are created directly from the Path are given higher weights.
Those created by linking to referenced nodes that are only mentioned but not included in the path are given lower weights
Those created through Machine learning are given weights based on confidence or other metrics.
Step 9 - Repeat steps 2 to 7
We repeat this for all the courses, curricula, videos, textbooks or other content we have to deconstruct.
Step 10 - Merge Duplicates nodes
Duplicate nodes are merged and maps are combined into the global map.
Now you have a big mess!
After deconstructing and mapping a number of courses, what you get is a big mess of a map that becomes almost impossible to navigate. We need to help the learner make sense of this data.
Dynamic, query specific views
Given the way we have deconstructed the nodes, established relationships, and mapped out the effort needed to learn each node, we can now create query specific visualizations of the map. When a learner asks a question like “ How do I create a business plan? ” we can visualize the relevant nodes, dynamically positioning them on the map based on their complexity in relation to the query. In plain english, we can map out all the concepts that lie between what the learner already knows and what the learner wants to know.
How are nodes positioned
Consider now a node that represents the concept of Pyramid Geometry. When looked at within the context of grade school mathematics, the position of that node will be at quite a high level, because there are so many concepts that are usually taught to kids before they get to concepts relating to geometry. However the same node could be positioned at a quite low level when learning about ancient egypt and their pyramids. The position of the node on the level scale is dynamic and is determined by adding the effort points of all those preceding nodes that it is connected to on the critical path within the particular query view. This will be different for each query, which makes the map a powerful tool, but also breaks the analogy when trying to compare it to a traditional map, or even Google maps. Here nodes don't live on a 2 dimensional surface, their position is only determined through the lense of a query. Each node exists within a multidimensional space the dimensions of which increase exponentially the more nodes we add to the map.
Machine Learning
At this point the map has been seeded with standard paths by the curriculum designers, generated paths by linking referenced nodes + keywords linked Nodes, and paths generated through machine learning. Now however we need to incorporate user generated paths. This can be done like a neural network, back propagating additional weight for successful student paths.
Pros and cons of the Learning Map built from existing material
A map built on the deconstruction of existing material, while not perfect, provides us a powerful starting point with which to seed the map. However, we should recognize that here all we are doing is deconstructing someone else's stories, and on it’s own this does not solve any real problem. It’s as if all we have done is break apart a few lego models and written up some manuals on how we could rebuild them. If there are any biases in the material, or if they are not teaching concepts in the optimal way, these issues will still exist in this deconstructed form. To make this truly powerful, we would need to deconstruct a large amount of material, from a variety of domains, and hopefully many courses from the same domains just taught in various different ways. The more of these paths we deconstruct, the more diversity there will be and the more options there will be for learners to create their own personal stories.
In the short term, before we have a large diverse number of paths, this type of learning map could still be a powerful tool for traditional schools, online platforms or businesses like Lynda.com (linkedIn Learning), and many other applications.
Approach 2 - Building from Standards [I will build out this section later]
Another approach we can use to build the learning map is to build it from extracting nodes from standards, like the US common core standards, European educational standards, or national curricula. Here we have pretty well defined standards we can convert into nodes. This method was tested when we were running the Moonshot Education Project, explained in this blog post: one-size-does-not-fit-all-overcoming-our-factory-education
Pros and cons of the Learning Map from Standards
Creating nodes through this process is relatively easy, given that much of the data is already structured and linked. However, similar to the first approach, this too is subject to bias.
Approach 3 - Building from Ontologies [I will build out this section later]
A third approach to building the learning map is to build it from an ontologie like wikipedia. Like building from standards, this is relatively easy as it again has well defined structured data, however, in this approach there are no learning paths within the ontology. Projects like the we.learn project by the CRI are leveraging this method and using learner generated paths to augment a map built on a wikipedia ontology.
We need to leverage all three approaches:
Through several years of experiments and research I've considered many approaches to creating the map, and I’ve come to the opinion that the best way to create it, is not to! The map should become an emergent phenomenon that's high-level structure is best defined by collective consensus and granular structure defined by the individual. Let me explain: In my first pilot we used approach 2 to create a map, and we based it on the US common core standards, and the Uwezo educational standards from East African. But basing it on these standards bakes into the map the biases of the very system that it's meant to redesign. And with it includes all the same issues, like, arbitrary levels of knowledge, arbitrary domains of knowledge, and biased pathways between concepts, "You need to learn X before you can learn Y". With approach 3, which is to base the map on the Wikipedia ontology, which is arguably the most comprehensive ontology of human knowledge, still includes the same bias, and in this approach there are no pathways between concepts, beyond hyperlinks, so we will need an additional mechanism to generate pathways. Approach 1 as described above which is to deconstruct educational material, map the concepts and the pathways that are generated and then go through a deduplication effort to combine concepts and come up with a map also still have challenges as discussed above. All three of these options have their issues, however, all three when combined are somewhat complementary: You have the institutional biases from approach 2 and 3 - Creating the high-level structure- counteracted by the practical biases of approach 1 -creating the personal low-level structure. But still, no one approach, or even a combination of all three is the best option. My opinion is to use these as seeds, with the explicit intent for the map to become an emergent property of the network, a map that may not even be human-readable:
If you consider traditional educational ontologies -maps of concepts, subjects and the pathways between them, Most are two dimensional, especially educational standards, which makes them easy for humans to understand and to categorize. Concepts have parent and child relationships, built in a hierarchy. Some more complex ontologies have 3 dimensions where they express parallel relationships, for example, while the concept of Pi is a child of a greater mathematical parent, it's also a cousin of various other concepts in maths, as well as concepts far removed from math like -Ancient Pyramid construction techniques. But these ontologies are at most 3 dimensional, and the three-dimensional versions become rather difficult for humans to understand. However, I've been experimenting with creating an emergent ontology with 300 dimensions, explained in later chapters, which is still nowhere near enough. I use the human brain as the minimum bar I am aiming for. Its neural connections are not built in 2 or 3 dimensions, on average every neuron is connected to 10 thousand others, and we can loosely imagine the brain as an ontology or map of concepts, concepts that when accessed in a particular path -neural pathway- can allow us to do things, like make coffee, sing a song, figure out quantum mechanics. These pathways are unique for each person, there is no one unifying ontology of the brain, beyond a high-level structure, each individual generates their own map of neural pathways over the span of their lifetime. And if the brain needs 10 thousand dimensions to do so then no wonder our 2 or 3-dimensional maps are so terrible.
We should at minimum aim to map out a ≥ number of connections as our barely intelligent human brains :)
Conclusion:
This learning map brick is a foundational brick, it acknowledges the context bricks it is built on, however it does not take into account what the world has already built and all the needs and requirements that existing educational infrastructure has. For example, I’m explicitly not taking into account the needs of traditional schools, institutions, textbook companies, accreditation bodies, etcetera, because all these have been built on top of a different context, one that was relevant 100 years ago, a context that is no longer relevant today. This brick is designed to give us the maximum number of options to build on top of. From here, we may choose to rebuild these same institutions if we deem it necessary, but this foundation brick should not be designed for them, they should instead be designed to work on the foundation. Recall the tower of pisa example I shared earlier on.
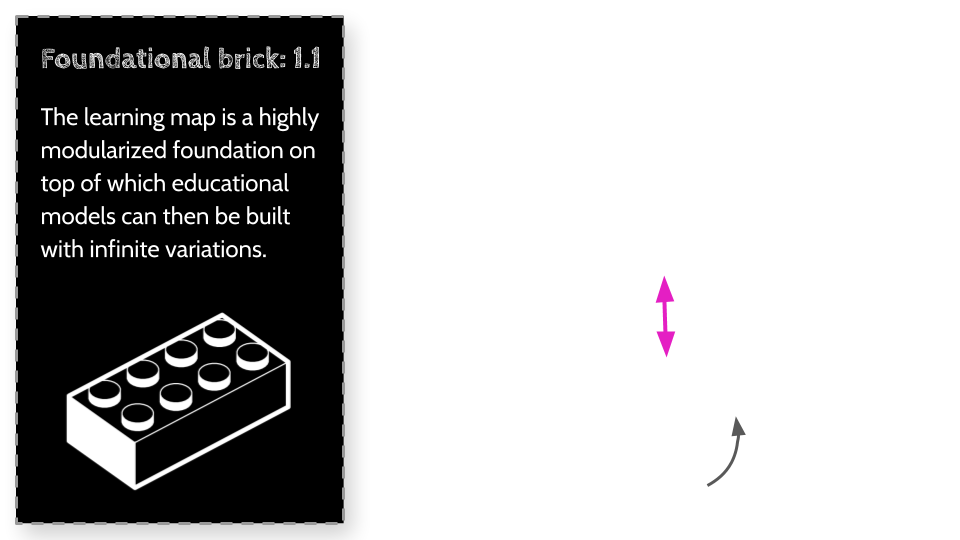
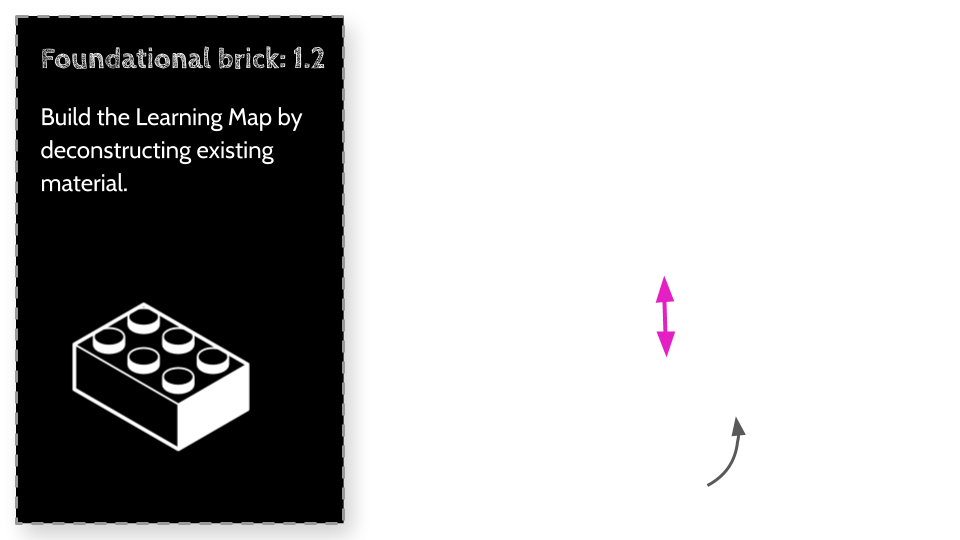
lego brick by Lluisa Iborra from the Noun ProjectFoundational Bricks - The Doing Map
Foundational Bricks - The Doing Map
The Doing Map: Open Social Innovation
This “doing map” brick, is designed to be built on top of and provide a foundational solution to the following contextual bricks:
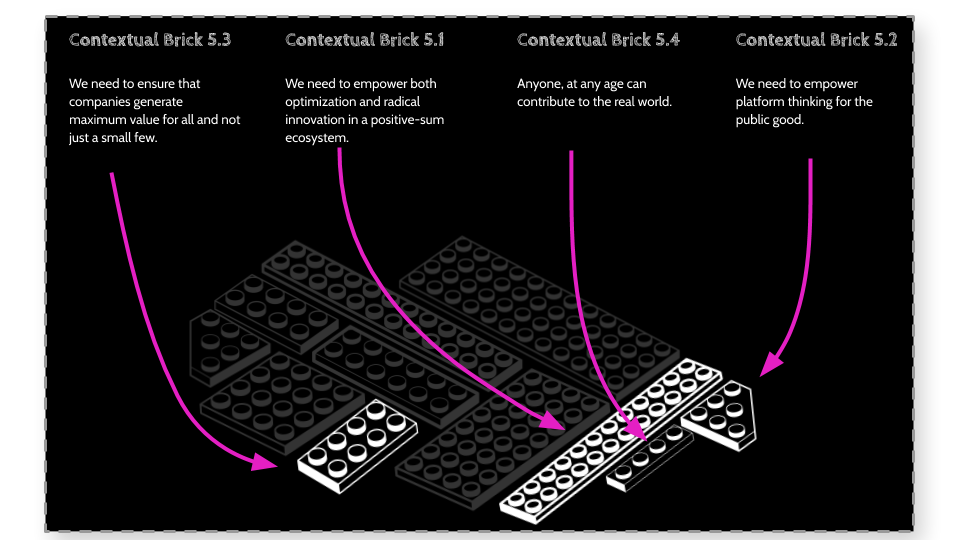
The goal of this foundational brick, is to build a mechanism that can rapidly accelerate the development of new ideas, businesses, and solutions to our grand challenges. If you recall contextual brick 1.1 to 1.4 that we need to re-invent almost all we do, this brick is to help us do so, while at the same time also addressing multiple other contextual challenges relating to education, context bricks 4.2 to 5.2. Together with the Learning Map, this foundational brick, The Doing Map work in parallel to compliment each other.
Here, much like the learning map is designed to modularize all the concepts that can be learnt, The doing map is designed to modularize all that can be done. As mentioned in the Two sides of the same coin paragraph, these two maps are closely related. A concept that can be learnt, and that is mapped on the learning map has close relationships with real-world applications of what has been learned, which is then mapped on this Doing Map. Learning and Doing, while separated in contemporary education and work, could and should be recombined to form a continuum. Each side boosting the other as you immediately put to practice the theory, and develop new theories through practice.
Open Social Innovation
As we discussed in the first few contextual bricks, there is a critical flaw in traditionally siloed innovation: radical innovation generally happens only once within closed systems. However, the process of Open Social Innovation generates solutions at an exponential pace, Let us discuss this in more detail.
An example of Open innovation - the doing and learning map combined.
Before discussing some of the mechanics of Open Social Innovation, I want to tell the story of a case study I've been exploring. It's a story of a non-profit that over the past 12 years has come to compete with some of the most well-funded organizations.
12 years ago the iGEM was formed, a non-profit with a simple goal of trying to help students who were studying synthetic biology to collaborate with each other across schools and teams, they would then award the best teams at the end of each year with a large celebration called the Jamboree. They had two simple rules: 1. Teams needed to work openly, sharing everything they were doing, and 2. they needed to make sure that what the teams were building, the synthetic biology, was interoperable, easily used by other teams.

Images: iGEM.org
As you can imagine the first two years came and went and the projects were pretty mediocre. but in the Third year, the students now had two years of work to build on, and suddenly they no longer needed to start from step one but could start from step three. In the fourth year, teams could start from step 5 and the next year step 8… and so their synthetic biology projects became more complex and useful. Now 12 years after they started, the quality of synthetic biology coming out of this non-profit is competing with the most well-funded research labs. In addition, due to the openness of the IP, it's causing it to become increasingly difficult for traditional labs to get patents, and pushing them to leverage and contribute to the open library, creating a feedback loop. These students not only get practical experience and a portfolio of work, the winning students get to choose their own salaries and pick where they want to work, or, increasingly, they just want to start their own labs.
Challenges that need to be addressed
However, iGEM and other open innovation organizations do have significant challenges, for example if winning teams are rewarded with status and job opportunities, how is that shared with the people who contributed to the 12 years of work that the winning team built their project on? In addition, how are economic incentives created in an ecosystem with open IP, and how is this all shared? I want to spend some time discussing these key challenges.
1 Licensing
2 Reducing friction
3 Incentive mechanism that works within an open ecosystem.
Challenge 1 - Licencing - A frictionless, open licence
Open licencing has come a long way in the past 20 years however, it is not where we need it to be to foster Super Collective Intelligence, the transaction costs are still too high. If we consider information within highly successful collective intelligent systems like our own brains, an Ant colony or beehive. Every time information is exchanged between neurons, ants or bees there is some cost, let's call this cost C. The more steps in a communication sequence the more cost is compounded. If a network were to communicate something to 10 nodes in that network, then the cost would be C X 10, and if it were to communicate that information to 100 nodes then the cost is C X 100. Therefore, if the networks of bricks we are trying to build here in this Open Social Innovation map are exponential, then the costs also become exponential. These exponential costs eventually compound to limit the potential of the system and we can see this in our brains, ant colonies and beehives. Human brains, which are about 2% of our body weight, consume 20% of our energy to operate, the energy cost of communicating between one neuron to another is minuscule, and yet due to the vast number of neurons the cost compounds quickly. In the brain, each neuron is connected to on average 10 thousand others, 1 billion neurons linked together by 10 trillion synapses, that's a pretty big exponential. This means that even a small increase or decrease in cost would have many orders of magnitude difference in overall affect. An increase of a few percentage points in cost, would result in you dropping tens of IQ points in mental capability. But the opposite is also true.
Today, if I were to go onto many open innovation platforms and search for something I need, say a design file for a 3D print, a piece of software code, or a template legal document, a lot of my time would be spent looking at the licence restrictions. This cost compounds quickly when each possible item has their own licence, and when each licence also has a large legal text to decipher. This is a serious limiting factor to open innovation, even a small change in cost here could drastically increase or decrease the overall effectiveness of the system. How small can we therefore make this cost?
The transaction costs of a license handling system, let's call it L, increases by at least N for every licence variant you add to the system. Even if the licence itself had no cost, I.E there were no licence then that variant would still have the cost of N, because the systems would still need to process which variant is being used, and that will incur a non-zero amount of effort we are calling N. lets say there are three licences in a system,
a Creative commence licence that allows you to do anything, let's say the cost is 1 effort to administer these easy licence requirements,
A Creative Commons Attribution licence where you could still do almost anything but you have to also provide attribution let's say the cost here is 2 effort to administer these conditions,
And a third licence, Creative Commons Attribution-ShareALike licence which adds an additional requirement to share any derived work under the same licence, let’s say the cost here is 3 effort.
The 1, 2 and 3 effort is the operational burden the requirements of the licence puts on those that use it. It takes little effort to implement the restrictions of a plain Creative Commons licence, therefore we give it a 1, but on the other side, administering the Attribution-ShareALike requirements takes 3 effort. Therefore the transaction costs of the licence handling system would be L = N x 3 + (1, 2 or 3) depending on the licence the transaction uses. And now you multiply that cost for every transaction the system needs to handle, which is when the cost becomes exponential. One option therefore to diminish costs would be to diminish the complexity of the licences -the 1, 2 or 3 effort it takes to administer the licence requirements. However, if we were to do that we would need to forego the power of a well constructed licence to generate the types of behaviour we want to try to incentivise. With less complexity we also have less control. The other option is to diminish the number of options, lets say we only have 2 options (1 or 3 effort), that drops the 2 effort option from the equation. This helps a lot, but given that exponentially increasing costs eventually grind a system to a halt, even a smaller cost will eventually slow things down. Is there a way to bring this cost down to zero?
An alternative, which could bring the L costs down to zero, is to have only one licence, a blanket licence for all, where the administration of the licence is made part of the infrastructure. In this case, we could remove the effort points from the equation as well as the N as there would be no variants. We can remove the effort points from the system, the 1, 2 or 3 effort, as we could move that cost of administration from the individual to the infrastructure instead, which would automatically handle the requirements as part of the process of communication. While this is still a cost, which is just shifted elsewhere, the cost is much reduced and the effort to process the cost does not burden the individual, but rather the network. The Network's resources can grow exponentially, while a node's resources on average cannot. Therefore we could theoretically have an exponentially growing network that keeps pace with an exponential cost and never needs to slow down.
This approach, while it does remove licence variants, it still allows us to define a singular well constructed powerful licence that incentivises the types of behaviors we desire, A licence we can update at any point and which is implemented in real time across the network.
To start off I see this licence as having these key parameters:
Creative Commons - All information should be completely open. By definition Open Social Innovation requires the innovation to be Open, no part of it should be hidden or obfuscated. In order for any information to be able to be used by anyone else it should be fully open.
Attribution - This allows others to distribute, remix, adapt, and build upon your work, even commercially, as long as they credit you for the original creation. While I have not yet described the innovation market, where attribution plays a powerful role, baking this licence requirement into the infrastructure of this foundational brick is required for the economic incentive models described in the innovation market to operate.
ShareALike - This allows others to remix, adapt, and build upon your work even for commercial purposes, as long as they license their new creations under the identical terms. This is important as we want to make sure that any derivatives of work created from the system are added back to that system and therefore fueling its exponential growth.
Challenge 2 - Reducing Friction - An Interoperability framework
Good open source works when you don't need to collaborate!
Let’s say I found the 3D design file, piece of software code, or template legal document I needed to progress with the project I’m working on. How can I go about incorporating that with what I already have? If you have worked within open innovation, or even within closed innovation teams in large corporations, using someone else's work and bolting it onto your own usually takes a mountain of effort. First you need to make sure that thing you found can take what you have, process it in the way you need and output what you desire. And to do that you often need to decipher what the creators actually made, and then figure out the many ways it does not work before eventually, if you are lucky, stumbling on the way it does work. In order for you to easily incorporate someone else's work, that work needs to be structured in a consistent transparent manner that can not only easily be found, but also easily be determined what the inputs, process and outputs are.
Let’s try think through this challenge using a tangible example:
let's say there is a new business startup who developed their business openly within an Open Social Innovation ecosystem. They somehow developed a water purification process which is highly innovative and could solve the global freshwater shortage challenge If only they could rapidly propagate their innovation throughout the world. How would they do this?
The closed approach:
To provide a comparison let’s first quickly describe how they would try to do this if they were operating as a traditional company not working within an Open Social Innovation ecosystem. Well, the business would probably try to raise a bunch of money so that they can scale quickly themselves. They would try to retain centralized control of the innovation so that they can extract the maximum amount of value from it personally and to pay back the investors. They would then spend the next decade slowly building up a global infrastructure, and fending off the many copycat companies who want to create their own versions of the same innovation. Even though they could have raised considerable resources, they would still only be able to devote a fraction of the possible available resources to optimizing their innovation. This centralized approach would slow down propagation and in the end could stifel further innovation for many years. A well documented example of this is from Bell labs who stifled innovation in magnetic storage tape, delaying its use by 70 years, Which is explained powerfully in a great book, The Master Switch by Tim Wu. But this is not really the fault of the business. Our economic systems are structured in a way to incentivise closed innovation, selfish interests and unintentionally, stifel collective intelligence and the common good.
The open approach:
So now let's look at how the business can propogate their innovation throughout the world within an Open Social Innovation ecosystem. In point 3 I’ll describe the economic and incentive challenges that will need to be taken into account, but here I’ll focus only on the mechanics of the challenge to share what they are doing with others through interoperable bricks. Consider that the business could include several innovative components Like a new desalination technology, a novel approach to a distribution chain, and a successful business model. Usually these are all looked at as a whole and if they are shared, would be shared as a whole. However this reduces the interoperability of the information. It requires the reader to go into great depth to fully understand what is going on, before they can use it, copy it, improve on it and rework it to operate in their local environments.

An example of how this could work is how good, well-documented open source software libraries are approached. Here, each component in the software library is modular, with well-defined parameters like; inputs (what the software needs to run), what it does (the processes it follows), and the outputs (what it produces, what features it offers...). With this framework you can easily search for those inputs, processes, and outputs, to find relevant pieces of code, and use them in other projects.
What would this look like if we applied this here to this example.
First, Instead of sharing the whole business as one singular project, we would share it as bite sized bricks. One brick would describe the water desalination technology, another would describe the supply and distribution chain, another would describe the business model. This would make it easier for someone —or an algorithm— to find, and combine compatible and relevant bricks in their own projects. For example, you may find that the business model of one project would fit really well with what you are doing (because the inputs and outputs are similar to yours, even though it may be operating in a completely different market). You may then find the technology from another project, and the goto market model from yet another. It's the ability to easily find bricks, recombine them, mix and match, localize... that would make it so powerful and drive exponential innovation.
So what could this framework look like
A current working theory is that we should document bricks as either:
a Theory of Change (If <X> then I expect <Y>. < document theory> <Document results>)
or as a Use Case (With <X input> and <Y process> we expect <Z result> <Actual Results, auto created>).
We would use the Theory of Change framework if the brick is in the early stages, and a Use Case framework once we have evidence it works and a solid understanding of how it will be used and implemented. The distinction between the two is important, A brick that is in the theory stage will want to remain open to all possibilities, and a brick that has found a theory that works now needs to start refining/productizing it and therefore should convert it into one or multiple Use Cases.
For example: Let's assume the (Desalination technology) is in the early stages and therefore use the Theory of Change framework. Then let’s assume the (Distribution chain) module is well understood and therefore we will use the Use Case framework.
Desalination Technology module: (If <we are able to use our unique manufacturing technique (more detail here) to create a salt membrane strong and cheaply enough (add parameters here)>, then <we will be able to radically improve the efficiency of the technology and reduce the cost per liter to (add metrics here)>. <Our approach to testing this theory is to refine our manufacturing approach <further documented here>. This is what we have done, this is our results so far...this is what we intend to test out next...>)
Distribution chain module: (With <our water purification equipment that works in (add details here)> and <Using local traveling merchants, who have in-depth local knowledge of tribes, their locations (more detail here, including links to assets, databases, code...)> we expect <to create positive feedback incentives within the whole chain (more details) resulting in marginal costs of (insert metrics here)> <Actual metrics will be calculated as this Brick is tested>)
Notice that the structure is really simple, there is a clear input, a clear process, and a clear output with results. Consider how easy it will be for someone to understand this particular brick.
Also, consider how easy it is to take this structure of use cases and to productize them. Most product managers use methodologies like Kanban, Scrum and Agile, this framework fits easily within these product management processes. This allows anyone wishing to leverage a Brick to quickly move into the development, implementation, and testing of it.
If the business were to operate within an Open Social Innovation ecosystem then the propagation and rapid scale of their innovation would take a very different course. They could still raise funds and investments however here any investment in one business is an investment in many, the investment is a positive sum, and multiplies across the network - explained in the innovation Market section-. In addition, the business is able to leverage the far more resources, where in closed systems you need to employ all those that work on your innovation, here you can leverage the innovation from anyone who is working, even if they are not within your particular team. Ultimately, the scale of the innovation is multiplied many fold, implemented rapidly and available to all.
Benefits of this interoperability framework:
Good open source works when you don't need to collaborate!
It can easily be structured and searched by humans or algorithms. E.G a project may be struggling with their go-to-market and distribution strategies. They can search for similar inputs and/or their desired outputs, and find relevant modules even if the modules operate in completely different domains. This generates diversity, serendipity, and unconventional innovation.
This structure makes it interoperable, easy to find, copy, fork, localize, test, and productize.
This works in all languages can easily be localized and leaves very little up for interpretation.
Structuring Bricks as Use Cases or Theory makes it really easy to start testing it or productizing it.
Built-in metrics based on how well a brick can process Inputs to Outputs can be measured over time. With these metrics we could have the network suggest Bricks automatically or have users search for modules that may be performing better than theirs. I.E the projects desalinization technology may be producing N results, through a search or automated recommendation the platform could recommend different modules, that produce N + X results
Notice how the Use Case framework and Theory Framework resembles the Scientific method and Lean Business methodology that are so successful at quickly getting to the point of testing an approach, objectively measuring the results and comparing them to expected results.
As a solutions designer you want to quickly get to the point where you can test your product out in the wild. This provides a “fail fast, fail Often” framework and incentivizes projects and contributors to think critically and remain objective.
Challenge 3 - Incentive mechanism that works within an open ecosystem.
I briefly described one of the issues with open innovation in the context of the iGEM, where top student teams are awarded reputation and employment opportunities based on their work, much of which was based on the work contributed by many others before them, yet who share in none of the reward. There are many other economic challenges and incentive challenges, and I’d like to discuss some of them here, to frame what we will later discuss in the solutions section and the Innovation Market.
So how could we reward everyone who at some point contributed to work, no matter how and when that contribution was made? Let’s first admit that there is nothing we have done which does not rely on contributions others have made. For example, everything I am writing here, although I am writing it, very little has come from me. Consider all the books I’ve read, the conversations I’ve had, the random ideas I overheard on the train to work, the lessons my teachers taught me when I was 8 years old, the boiler plate wizdom I read on the inside of candy wrappers, all of this had some impact and contributed however little to what is being written here. We are standing on the shoulders of the billions that came before us and at the very most, even the most original idea, has little to do with our own contribution, our contribution is only the latest piece. Having said that we do still contribute and we do still have some claim in what is produced. Every action we take has some type of value. What is extraordinary about the time we live in now, is that for the first time we can calculate the value of these contributions and track them in a decentralized ledger where anyone can objectively calculate the proportion of value each contribution has provided to the whole.
Calculating Value of granular tasks at an individual level:
First, let us discuss how value could be calculated, because if we are able to determine value, then as soon as any contributor adds that value, they could be rewarded some type of token which later could gain additional value, based on where that contribution is taken, even by others. To do this, let’s use another tangible example: If we focus specifically on the work that goes into running a business, let's say a business that produces and distributes mosquito proof bed nets:
The work the business does is a combination of tasks, and every task, when completed has some value. In a traditional model, Investors, or philanthropy gives money to the business that has been vetted, and through that businesses' opaque internal processes they then decide how valuable the large collection of tasks needed to create the bed nets are and assigns them to be completed according to their priority and budget. Usually, this is done through budget meetings and internal project management meetings. These decisions about the value of tasks are usually based on guestimation, they are slow to change when data changes and are prone to get stuck in the "sunk-cost" feedback loop. This is where the value of a task is based on its perceived value + the resources that have already gone into completing that task to date. This skews the value of tasks dramatically, which is why we see such tremendous amounts of resources going into tasks that on their own produce little value. An example is Kodak, investing in their traditional film business, as opposed to the digital camera they invented. Here the value of the tasks are artificially inflated due to the calculation of adding sunk-cost, and we grossly underestimate the negative effects this has on innovation. While it is useful to take into account sunk-costs for businesses that need to prioritise stability over innovation, this calculation should be explicitly made, we need to know what portion of the value is sunk-cost so that objective analysis can be made. The task value calculation should be something open, so that businesses that want stability can value the task separately, to those that want innovation. This therefore implies some type of task value market mechanism where separate parties could come up with seperate values for tasks. How can we re-engineer the value calculation of tasks to be open?
One place we can look for inspiration is how we value stocks and bonds, the same can be applied here to value tasks in two distinct ways over time; internally by the business team, or externally by the Market.
Every novel task (Like building a new website for the project) or recurring task (like processing the project's invoices) has some value. Traditionally, we don't really think of each task as having a value, we usually just group tasks by department or employee, give the department or employee a budget or salary, and then it’s up to the department or individual to stick to their budget. Ultimately, if the business does this explicitly or not each task is assigned a value, and for the sake of comparison, let’s assume the cost of making this value calculation is N.
What we need to do is to make this calculation explicit for each task, but we don't want to add additional cost to the system to do so, as additional costs will compound exponentially. Therefore our aim here is to at the very least keep the cost less than or equal to N.
Just like traditional systems, the value calculation can be as detailed or as high level as one likes -we will get to the quality of the value calculation later, let’s just focus on getting a value to begin with and later we can discuss how to improve its quality- One example could be to have the value calculation be a calculation based on time spent on a task divided by budget, this is something that could be automated and therefore have an equil cost of N.
Another option is to outsource the value calculation to the market if you are willing to relinquish control. For example If the business did need to do a task, they could present the task to an open market and offer Y reward for it to be done, the market could then bid to do that work and therefore value the task based on the bid, in this case what ever the Y turned out to be, this would result in a market based value. A good example of this is Upwork, or Fiverr. This approach would have a cost equal to N if no interoperability framework were used, however a cost of less than N if an interoperability framework were used.
Another approach could be to combine the two in a process that would be very familiar to agile software development teams: The Business team and or the market determines the estimated effort a task needs to be completed. A good way to do this is to use the Fibonacci numbers (1, 2, 3, 5, 8, 13, 21, 34, … ) to estimate effort. We use the fibonacci numbers because humans are good at estimating effort when it comes to small tasks but not when it comes to big complex tasks and the fibonacci numbers are weighted in such a way where our deficiency is compensated by the added weight of the higher and higher numbers. Let's look at an example: Consider two tasks,
1. move the website "learn more" button from the bottom to the top of the website, and 2. write a case study about the sales and marketing results of the last big campaign. The team and/or the market can determine the estimated effort the task needs to be completed. Task 1 could have an effort of 3, where task 2 could have an effort of 34. The team/and/or market can then bid to complete those tasks and if completed successfully would validate that task's value as estimated. Now the costs of valuing tasks this way would be equal to N only for businesses, like agile software developers, who already use such processes, however would be greater than N for businesses who don't yet use this process. If you outsource this calculation to the market through a bidding process, then you could reduce the cost to below N.
These are some possible approaches we could use.
Rewarding Contributors:
Now let’s assume we have determined the value of a contribution to a task using something like the above methods discussed. Let's now consider the challenges around providing a reward. Remember that we are considering this within the context of Open Social Innovation where everything is open and can be used by anyone within the network.
Here are some minimum requirements I believe we would need.
Each contribution is initially singular, just like in closed innovation, where you do one task and you get paid once for it by your employer. The same initially applies here, therefore the initial reward should be earned when completing a task in a particular brick. We could use similar methods to how we reward people within traditional closed innovation businesses, you get paid in cash or equity. Equity in this case would be in the form of tokens in that brick, tokens being similar to shares in that their value is dynamic and determined by the market. A key to consider here is that even if the the individual gets paid in cash, each time a contribution is made, an equivalent number of tokens are generated. Each contribution therefore dilutes the total. The importance of this concept comes apparent when looking at the next key requirement.
In open innovation however, a singular contribution can be multiplied many fold, which is why open innovation is so powerful. So how can we ensure that contributors to the original brick are rewarded when the brick is copied. One method, which has come out of work being done by Thomas Maillart could be to allow each brick to have its own token and each token have its own value. When the original Brick is copied. The copy generates its own token, we can then arbitrarily give the copy 200 of the newly created tokens to kick it off, the copy then retains 100 tokens (50%) and the other 100 (50%) is given to the original Brick and shared with the original contributors based on how many tokens they hold in that original brick. Now as an original contributor, I don't mind that someone has copied my work, as I now own a portion, upto 50% of that copy, and if they are successful, the value of my tokens will increase (see illustration above).
To drive further value we would want to make sure that Tokens could also be traded in secondary markets so that they can drive further investment if innovative bricks and interest in newly created bricks which do not yet have proven value. Investment also counts as a contribution, just like you could purchase shares in Apple, you could purchase tokens in bricks.
We need to ensure that the earning tokens for contributions method is explicit and openly documented. Contributors can then decide which method and therefore brick they would like to contribute to, incentivizing good behavior and fair contracts.
The Coin, preview - a preview of the upcoming Coin chapter.
We have a whole chapter discussing the connection between the Learning Map and the Doing Map later in the paper, but as a basic understanding of it is relevant for the remainder of the Doing Map chapter, I’ll briefly describe it here:
The coin body could be seen to represent the various accreditation and qualification bodies that sit between us learning things and us doing things. Usually this is a school certificate, a degree, a masters, a PhD or any number of qualifications and accreditations that are supposed to be an objective measure of what we know and therefore of what we could do. This is what employers, hiring managers and society as a whole uses as a method of quickly determining knowledge and skills. However, without going into detail why these bodies are a really poor approach at solving this requirement, let’s consider how the learning Map and Doing Map could remove the requirement of us to even have these types of bodies.
As recently discussed, Tokens have dynamic value and are rewards assigned to individuals based on them completing tasks within bricks. Bricks are tagged to skills (actions that can be done), Bricks are linked to Nodes and nodes represent concepts that can be learned on the learning map. Therefore, we have an objective, market-based method of determining someone's knowledge and skills. Two candidates with the exact same qualifications, I.E both have completed a node on the learning map, can be objectively judged by looking at the market value of their contributions to various bricks, which is an application of what they learned. If an employer was deciding between two candidates who have learned the exact same nodes, they could refer to the objective, market-based value of the candidates contributions on the Doing Map.
How the Doing Map is created:
We have now discussed at a high level what the doing map is, how it is built for an ecosystem of Open Social Innovation, how a system like this is used within the iGEM example, some of the issues with the iGEM and other such systems, and then some possible solutions to those issues. Now let's bring this together somewhat and describe some ways the Doing Map could be built. Much like the Learning Map has various options to how it can be built, the Doing Map also has options, and again these options could be run in parallel as complementary methods.
The structure of the Doing Map:
In the previous Learning Map chapter, we discussed how we could deconstruct curriculum, courses, videos textbooks and a whole host of other material into concepts that we can then map to the learning map. If you recall, Nodes would be the most granular component, each node could then have multiple pieces of content tagged to it and then that node would be linked to other nodes to create many paths. Here we can do something similar with businesses and the bricks that they are made of.
If courses, videos, curriculum... are Paths in the Learning Map, then Businesses, Supply chains, departments... are Processes in the Doing Map
If Concepts that can be taught and assessed are nodes in the Learning Map, Then tangible products, actions, innovations... are Bricks in the Doing Map.
And if items like videos, text, tools, people, resources are content in the Learning Map, then work products, methods, Code, databases, files… are Resources in the Doing Map.
Building from Project based programs within schools and universities.
To describe this approach at building the map, let’s follow a tangible use case, the use case of a student team working within a project based educational program. For a real-world example, you can review various programs we have worked on that follow this process here: The CRI
Build through funding and grant competitions
To describe this approach at building the map, let’s follow a similar tangible use case, the use case of a team taking part in funding or grant competition. For a real-world example, you can review various programs we have worked on that follow this process here: XPRIZE.
Bricks, Resources and Processes
During the above two examples, in the background the Doing Map is generated, similar to how the Learning Map is generated.
Which results in a map similar in structure to the Learning Map, and which could then be leveraged to accomplish similar goals.
Now queries like “how can I build a vertical farming business” could be answered with a map of bricks, example solutions and a visual the inputs and outputs of all related bricks, and processes. More on this later in the Solutions section.
How every stage of product development benefits from Open Social Innovation:
Now let’s consider how each stage in the cycle of innovation can benefit from Open Social Innovation.
Design stage in cycle
The design of solutions can benefit from leveraging what has already been developed, through processes like:
Recombination - Recombine parts of solutions to create something new.
Localization - Take an existing solution and localize it to your particular local and/or cultural context.
Bolting together - Combine ready-made solutions to create more complex ones that address a bigger challenge.
Build stage in cycle
The Build portion of a cycle can benefit from leveraging the cognitive surplus of individuals you would never be able to employ yourself. Consider that within traditional organizations you can never hope to employ all the smartest people to work on your innovation no matter how well funded you may be; you are always constrained. However, with Open Social Innovation where it’s structured as a common good, you can tap into the cognitive surplus of innovators even if they are employed elsewhere. There are over a trillion hours a year of human resources available to contribute to open projects[8]. This cognitive surplus is vastly under-tapped by open projects.
Test stage in cycle
The value of a test is directly related to how confident one is in its setup, how amenable the test is to objective, quantitative evaluation, and the reproducibility of its results. We propose structuring these test within an interoperability framework that openly publishes test results so that anyone can learn from them. Consider how rapidly solutions can innovate if their assumptions are known, their methods for solving and evaluating the solution are transparent, and their input and output data are open for scrutiny
If you know solution X is better (e.g., more efficient, more cost-effective, more convenient), than solution Y, and that the assumptions, methods, and data are objectively defined, open, and transparent, which would you go with? Funders, investors and customers have significantly higher trust when there is transparency.
Analyze stage in cycle
Consider how many experiments and assumptions are being tested in the millions of companies and projects being run every day (e.g., business models, products, distribution systems, novel technologies, etc.). These data and analyses have limited value and stagnate when they sit within closed siloes. Open data, structured in such a way that makes it easily leveraged (discussed in detail within the interoperability section) will allow for open research, radically increasing what can be learned.
In an ecosystem where innovation is set up as a Common Good available for anyone to leverage, sharing data allows you to leverage the collective intelligence of the community, intelligence you could not leverage through traditional ecosystems.
An Exponential Explosion of Innovation
As more teams and students add their bricks to the library, the more complex and mature the bricks would become, similar to how the iGEM initially had mediocre projects for the first few years and now generates projects that are competing with some of the most well funded research labs. Consider what can be achieved if we were to use a similar approach to solving grand challenges, like poverty, climate change, renewable energies... In 15 years we could have open solutions rapidly improving, being implemented globally and solving challenges our most well-funded organizations are battling to solve today.
This approach could create a generation of students who embrace open-collaboration and who would then be moving into leadership roles throughout the world, further establishing the model. Just as important, we would have solved one of the biggest challenges in education: To move it away from a one-size fits all passive model where kids learn to sit, do as they are told, learn random facts, and pass standardized tests. And move it to one where they would enter a lifelong learning world based on challenge-based learning, continually learning the very skills so critically lacking in graduates today like creative problem solving, teamwork, collaboration, critical thinking excetra.
Prototype Platform for Open Social Innovation
Link to mockups: https://invis.io/C5NWAHL83MA
learn from millions of ideas, experiments, approaches, failures, and successes.
Tap into the cognitive surplus of innovators you could never hope to employ yourself.
Access and contribute to collective intelligence
Build a portfolio, network, experience, skills
Funding and Marketing opportunities

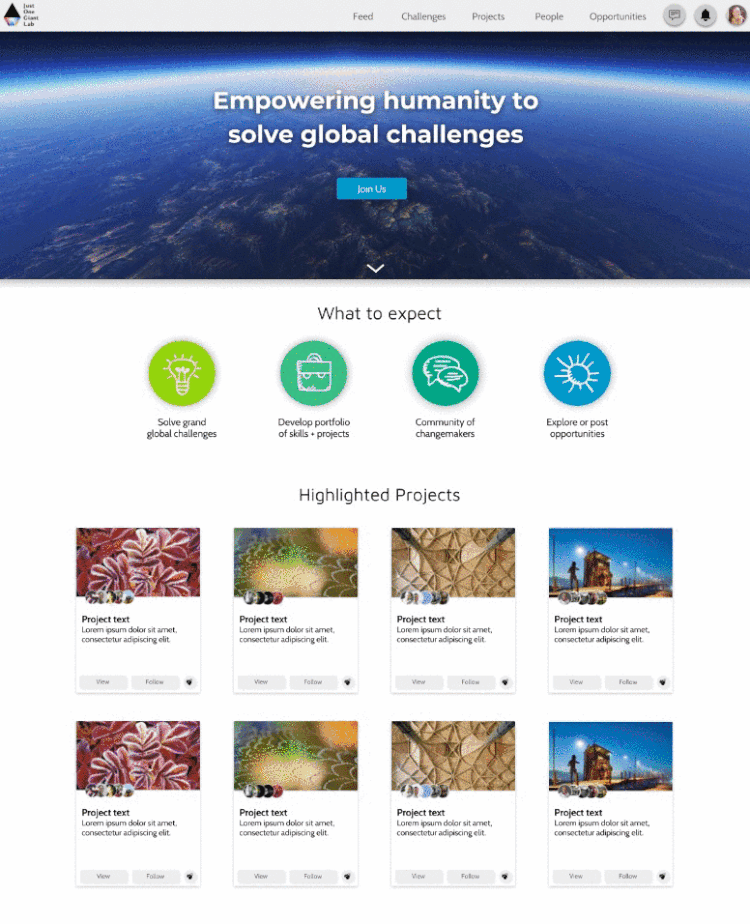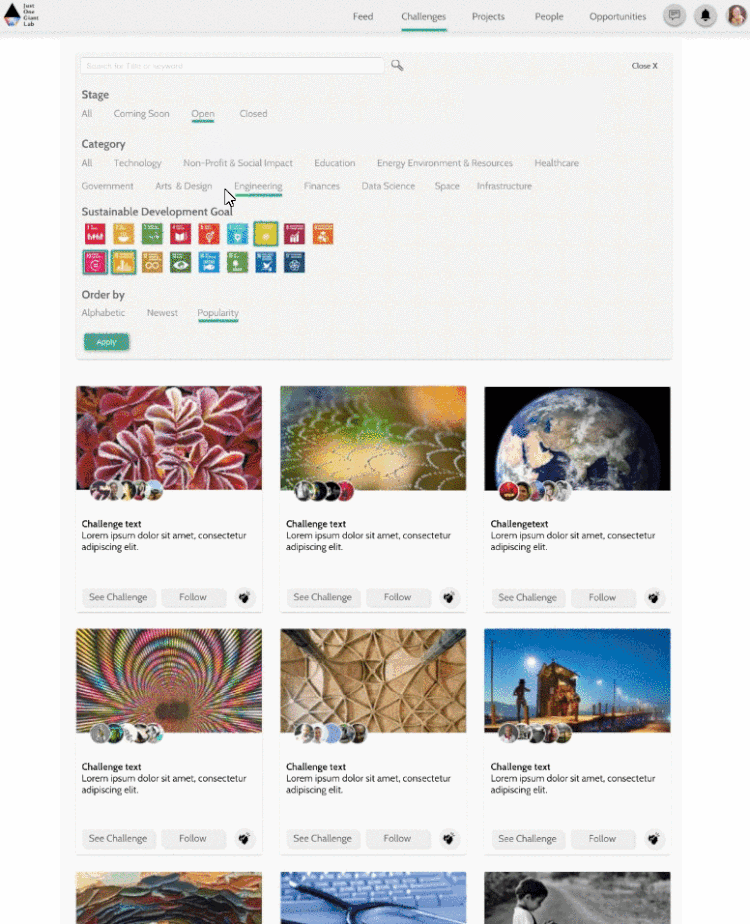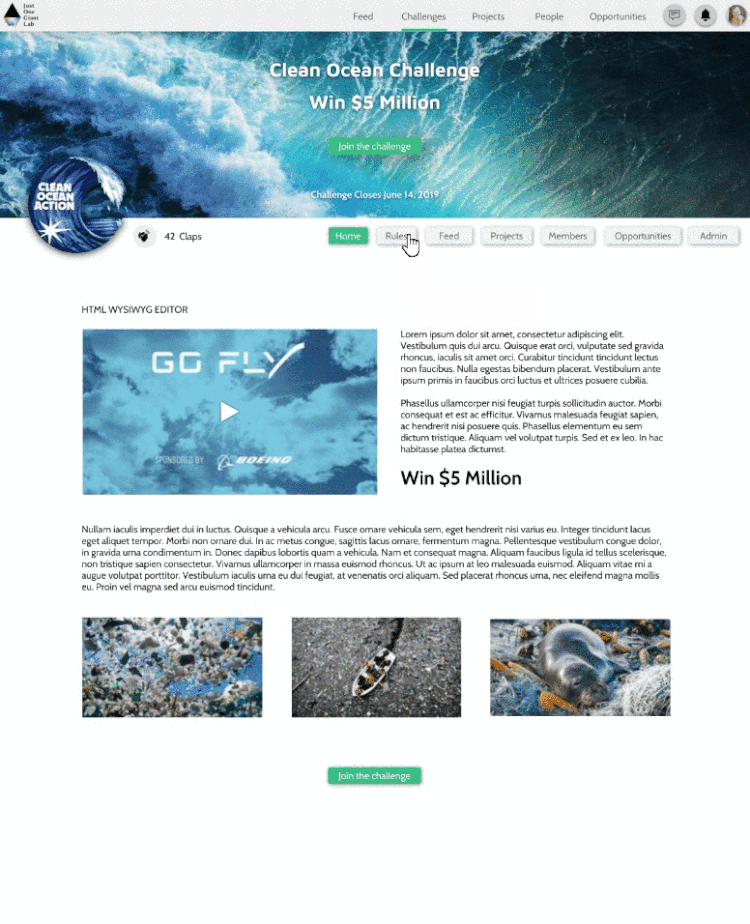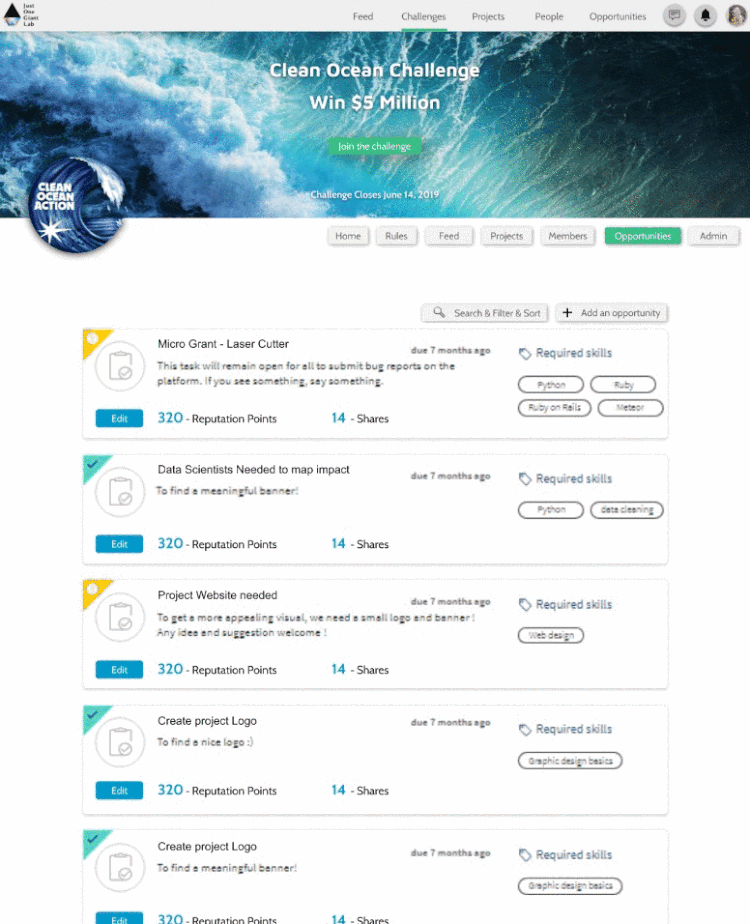


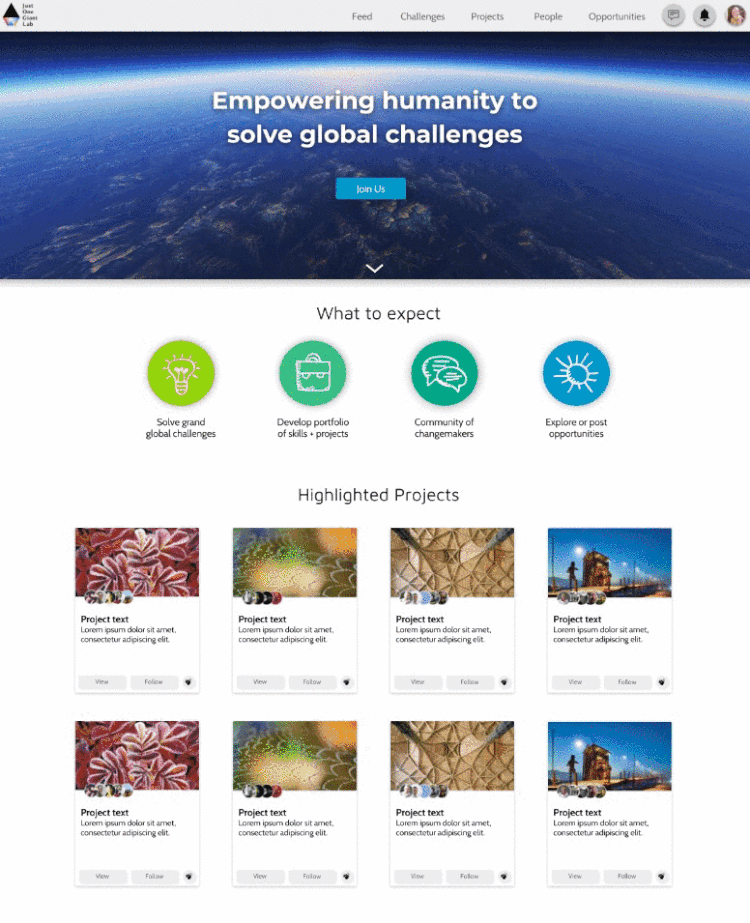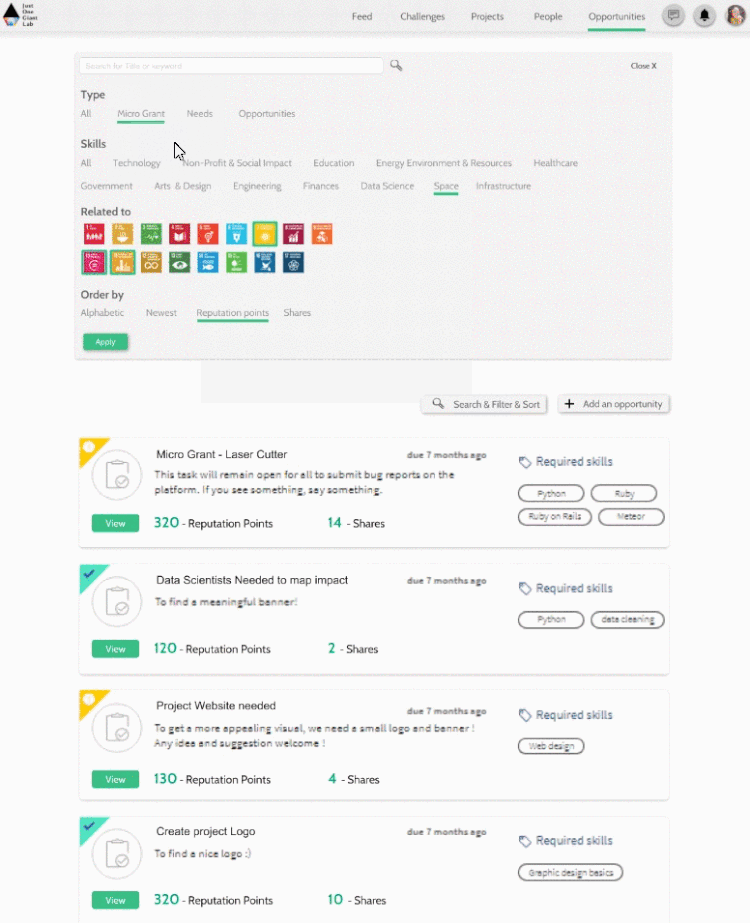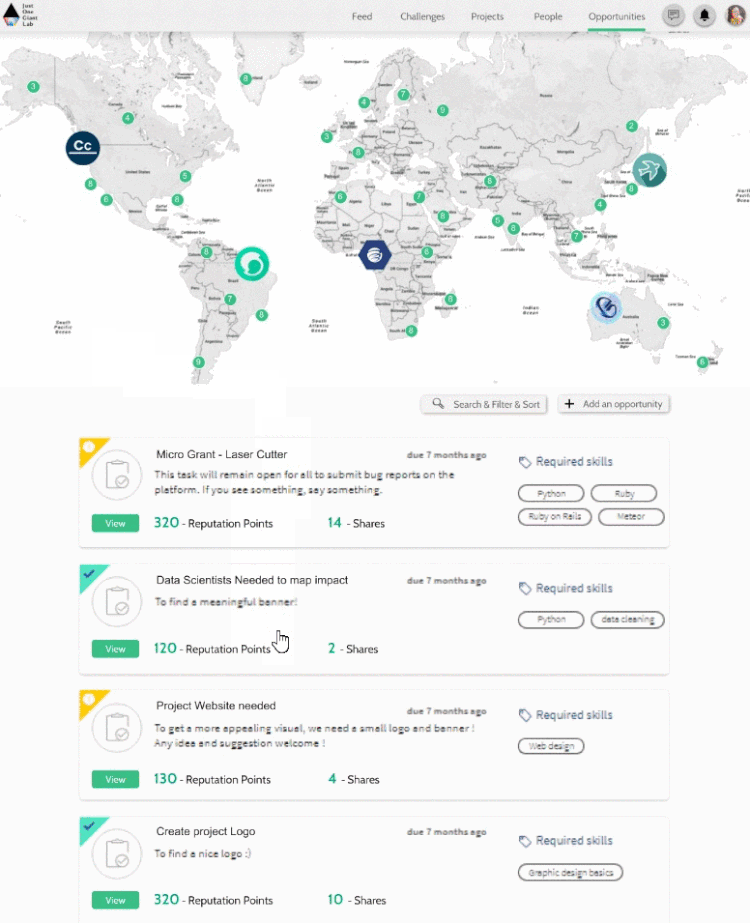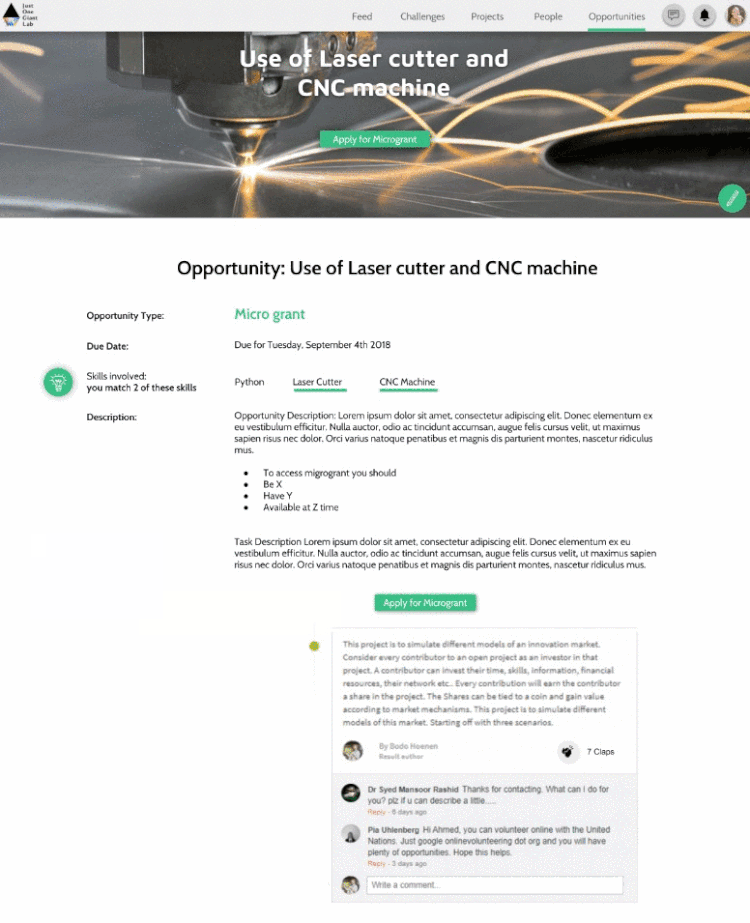

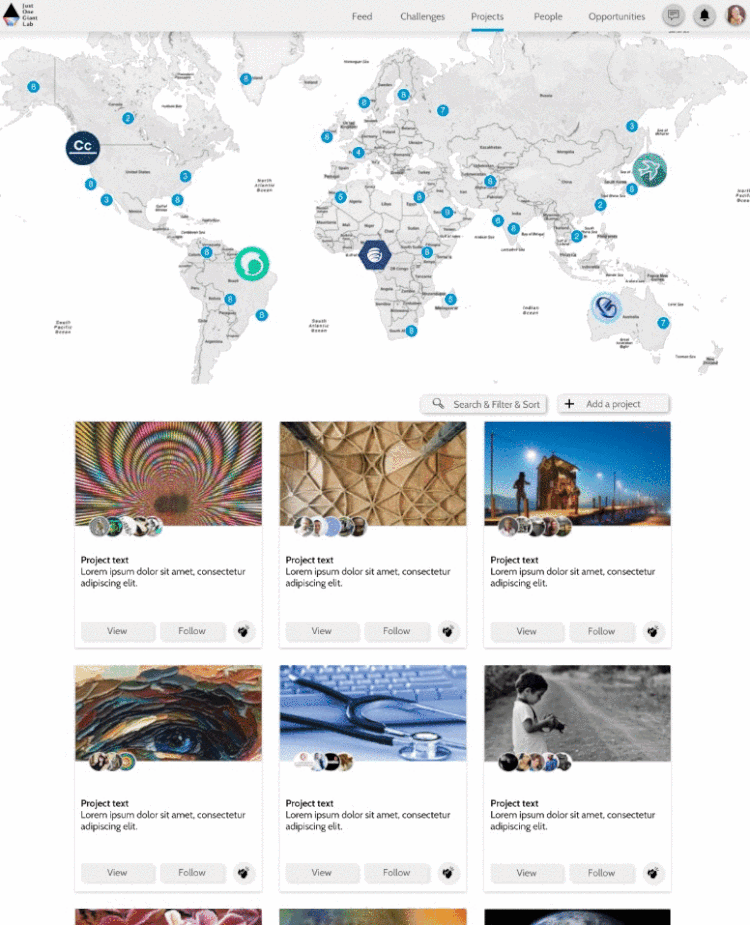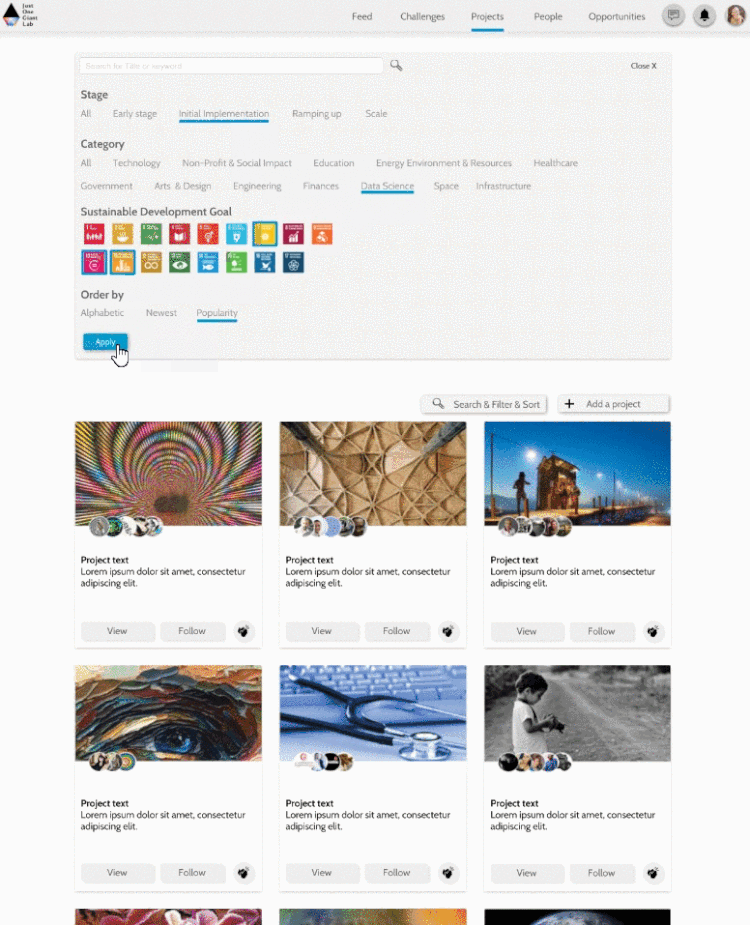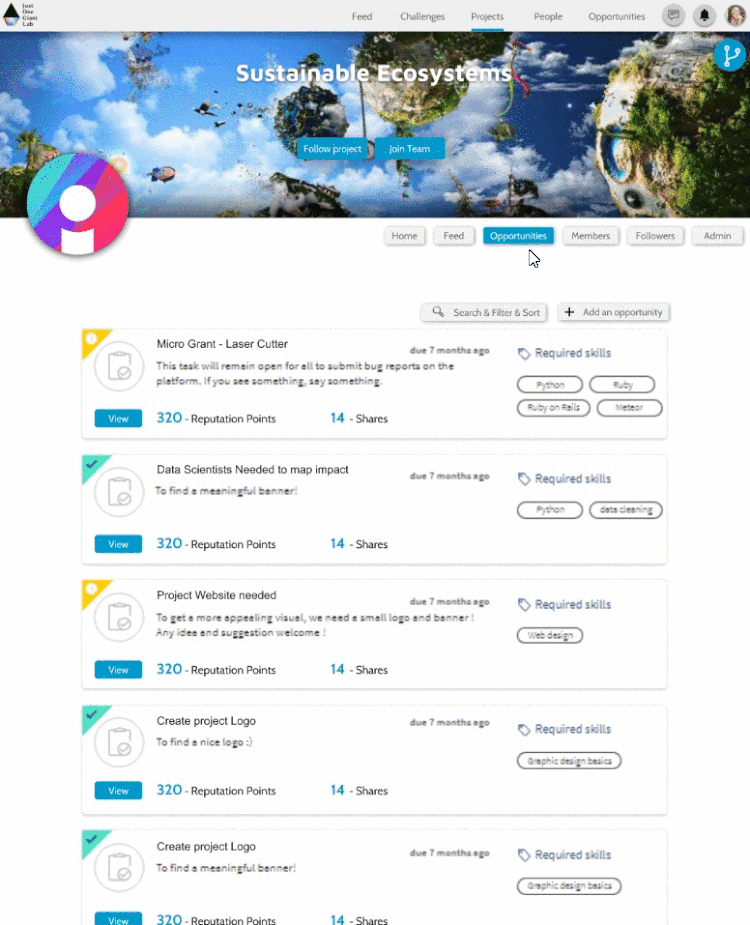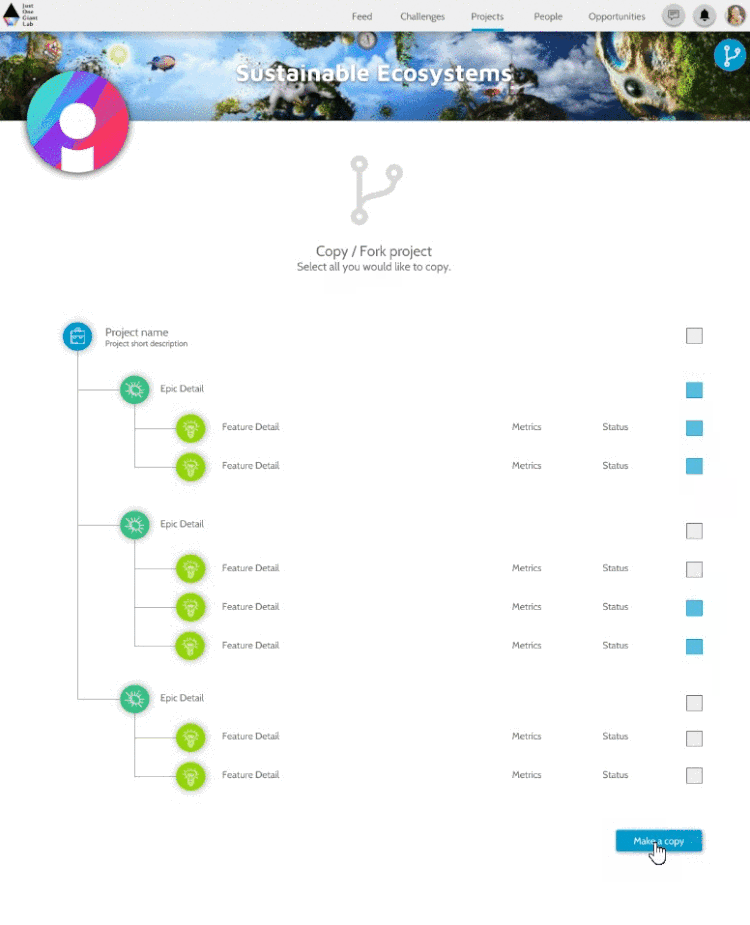
Conclusion:
The doing map is a number of bricks that form a foundation that enables collective intelligence to emerge. It’s built with the following bricks:
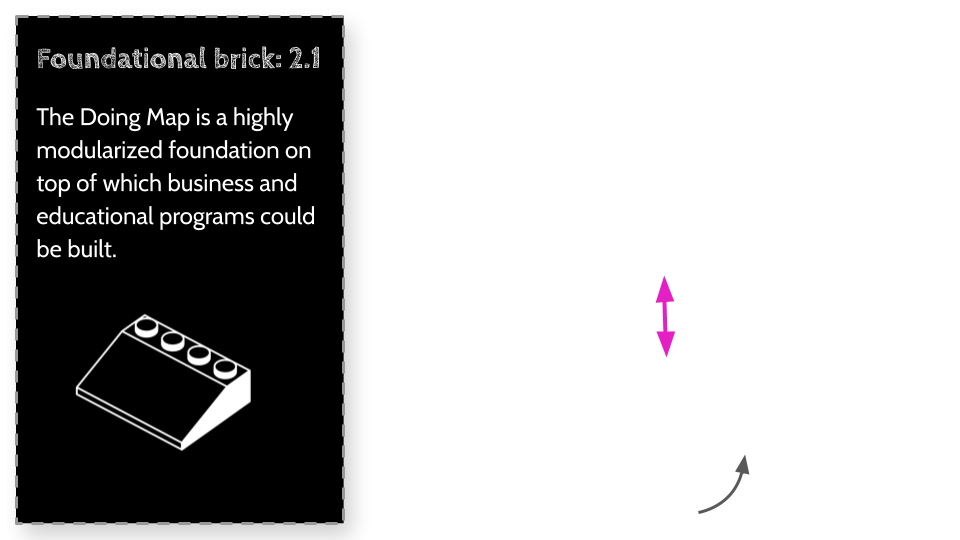
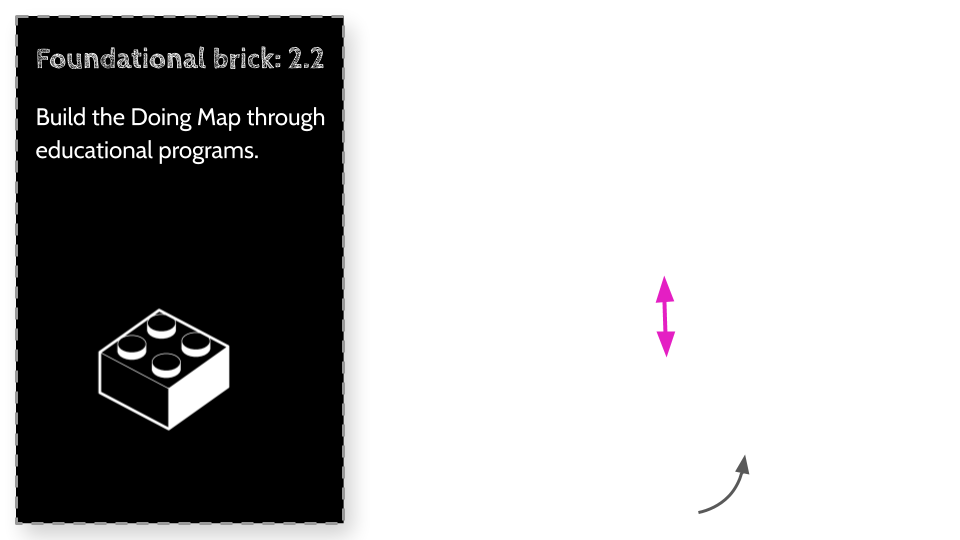
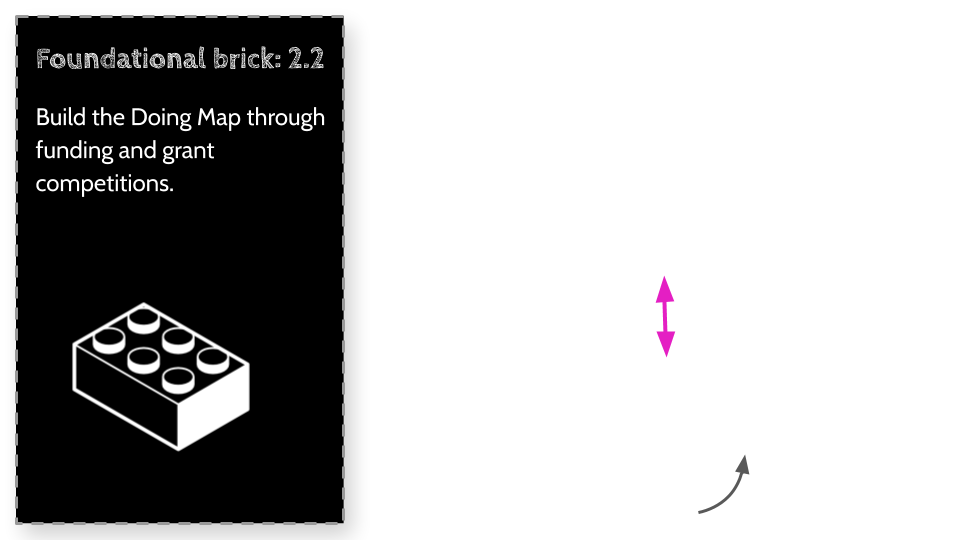
lego brick by Lluisa Iborra from the Noun ProjectFoundational Bricks - The Innovation Market
Foundational Bricks - The Innovation Market
Leveraging current trends:
There are a large number of global challenges, including the many that are contained within the 17 United Nations Sustainable Development Goals (SDGs). They set an agenda to make the world more sustainable by 2030, and are supported by 193 countries who have committed to drive solutions to these goals forward.
In addition, there are 1.3 billion students in the world, most feel disengaged from the learning process but are highly concerned about the world’s biggest challenges and want to act !!!
With this government support and the societal change being brought forward by our youth, this is a powerful opportunity to change the way the world works.
Market Mechanisms - Market-Based Governance:
Much of this chapter was inspired by the work and research from Thomas Maillart and the University of Geneva (Who I have worked with on numerous projects).
how Tokens are earned
Tokens are earned within bricks by contributing to them. In addition, when bricks are copied, the contributors to that brick are rewarded with tokens in the project that uses it. Both Projects and individual innovators can build sustainable businesses.
Instead of a brick only being used by one entity, in the innovation market It’s impact can be multiplied many fold, it can be used by thousands, each providing the contributors to that brick with value.
What happens for new users ?
New Projects - All users get tokens according to their contributions they make to projects
Existing Projects (Experimental) - if user register with an existing project from Github, the value of past contributions are back computed, based on value history of projects registered on OSI.
Trading rules - High Level
Users can trade tokens of any project using their OSI$ cash
Short selling is possible (to allow the price of a project to go lower even if the trader does not hold tokens of the project)
From their contributions & trading operations, users get a portfolio of token holdings from various projects
They can trace the evolution of their assets, and overall portfolio.
Impact Multiplier
When Projects are invested in, they improve their bricks that make their company work. This investment is multiplied manyfold throughout the network, which feeds back again to the project. It is a positive sum economy - An investment in one is an investment in many.
Using the illustrated example below:
Investment: Project aqua is awarded $100K, the project’s tokens increase in value which increases its visibility to gain further funding and further contributions because now the tokens awarded to contributors are worth more.
Multiplier 1: The social impact is multiplied as the bricks of one project are used by other projects in other domains that help more people.
Multiplier 2: The economic effect is clear once tokens enter secondary markets. If a brick from Project Aqua is used by other projects the tokens of those Projects can be expected to raise in value accordingly in secondary markets. Because project Aqua owns some of the tokens in these projects as a function of them using its bricks, project Aqua is rewarded for sharing their bricks.
Market Setup
This was written up Thomas Maillart .
THE BELOW NEEDS TO BE UPDATED, High-level details only:
Content and Share Attribution:
Possibilities for share attribution :
When tasks are set in a project, they are pre-valued by the community within that project and put into a backlog of tasks.
They are voted on by community, votes are affected by the reputation of the person voting and the domain within which the task falls within (EG a backend developer will have greater reputation when the task involves databases, than when the task involves marketing collateral)
When a task is accepted by an individual or group a smart contract is setup.
On completion of task, we use peer review to review task
Both the task contributors and reviewers are rewarded with the pre-defined value the community placed on task.
Proposed Mechanisms:
Short selling (liability up to wallet and shareholdings, i.e. a short seller may lose everything if the traded project becomes very successful)
Slow market: one transaction per minute per user.
Increment: 0.1
Reuse & Fork:
One should be incentivized to reuse parts of existing projects
Reuse is free but incumbent contributors should be rewarded for their past work. When content is reused from one project to another, the stockholders of the incumbent projects get shares from the reusing project.
X% (TBD, example 50%) of the shares of the latter project are distributed to the individual having performed the reuse. X% (TBD, example 50%) of shares are spread across the shareholders of the incumbent project in proportion of their respective holding in the incumbent project. In case of fork, the initial stock of shares in the latter project is set arbitrarily to 200. The incumbent shareholders immediately share 100 shares of the forked project and the individual having forked gets the other 100.
Valuation starts at 1 and initial capital is 200.
Fork of intermediate versions is possible. Distribution of bonus shares to incumbents is made according to the contribution and stock values states at the time of the version.
Fork may, for instance, allow rebooting of a project, which has experienced a governance failure.
Expected behavior: a fork is pure replication of content, which brings no additional information. Therefore, if the project does not bring expectation that it will distinguish itself from the parent project, it should lose traction and thus value fairly quickly. Another possibility would be that it reaches the same value as the incumbent project (since they both contain the same information). However, this is unlikely because the value of a project entails its capacity to grow and adapt. For that community building is almost required. If the forked project strives with another community, then the fork is a success and the project gets its own value.
Updates to previously forked projects or modules:
If a module or project which was previously forked from another project is updated, the project that pulled it should be notified. Also in the reverse. If the project that made the fork is updated, the original project should be notified. As discussed above in the Interoperability section notice that bricks will have a structure that also includes Expected Vs Actual metrics. This is a powerful way to objectively see the performance of a brick... and plays out like this:
Person A’s module metrics show that their manufacturing process incurs X cost
Person B forked that module and now achieves a cost of ½ X
Person A is notified so that they can pull back that innovation into the original. The same Share allocation process applies.
How does it translate into real money?
The objective is primarily to encourage circulation of capital as a way to reveal the true value of projects through a market mechanism.
Optional conditions for use of cryptocurrency to buy supply :
min. 1000 transactions and 100 different traders. To protect shareholder, only up to 20% of the capital can be used for supply in cash. Tickets must be uploaded/contributed and peer-verified by 3 humans (TBD, possibly decentralized accounting through a kind of mining)
Alternative: use own crypto-cash wallet, and seek reimbursement to the project through peer-verification (accounting mining).
Upcoming Chapters
Upcoming Chapters
The following are the chapters currently being written
Context Bricks
Our Ignorance is increasing [needs to be updated, see below]
Foundation Bricks
The Innovation Market
Solution Bricks
The Learning Map Tool
The Doing Map Tool
The Coin - Accreditation and qualifications
The Serendipity AI
The Innovation Market
Content Generation Franchise Model
Implementation Bricks
Platform for the common good
Franchise Model
UNESCO, the CRI and the Learning Planet
Scale Bricks
People of the world and beyond
United Nations
Franchise Model
When analogies Break Down
Error Correction